炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:华泰证券研究所)
人工智能100:AI量化的过去、现在与未来
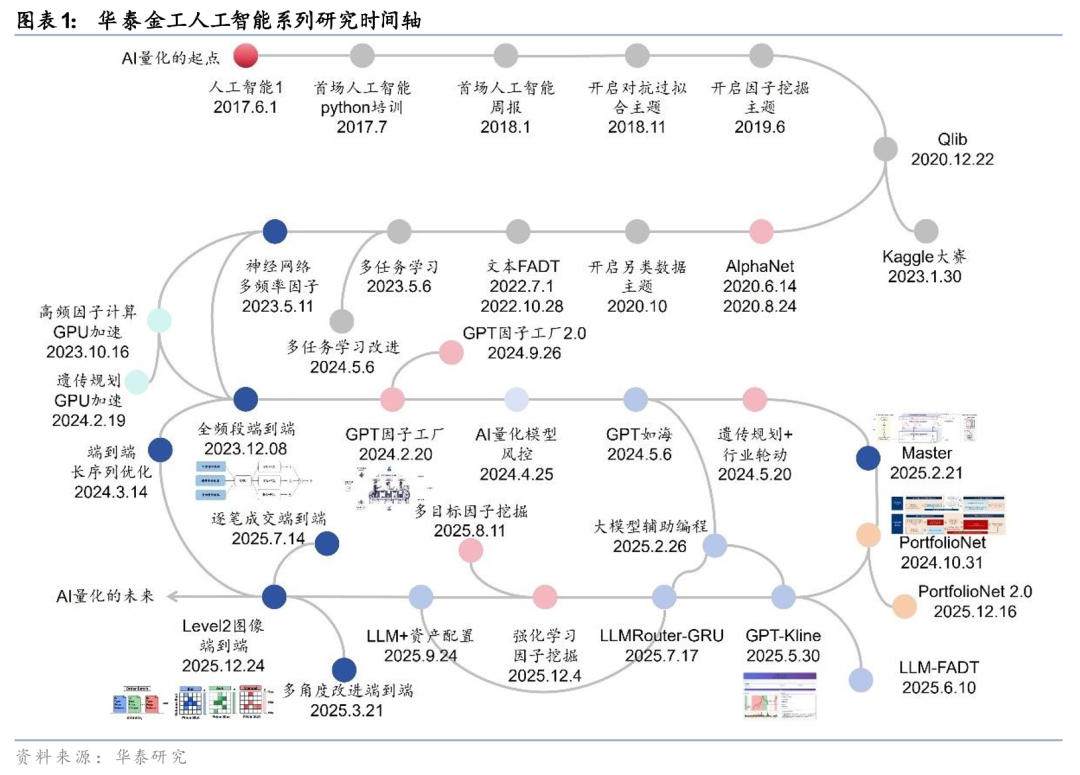
本文是华泰人工智能系列的第100篇研究报告。过往的八年半里,我们亲历了量化投资行业的这场深刻变革:技术路径上,从早期的机器学习,演进到深度学习,再到如今以大语言模型为代表的新范式。应用场景上,从早期的因子合成,拓展至因子挖掘与端到端建模,进而渗透到组合优化、行业轮动、资产配置、流程管理等投资的各个环节。行业认知上,从最初的质疑与观望,逐渐转向接纳与尝试,直至今日的全面拥抱。第100篇研究,既是对过往足迹的回顾,也是对未来征途的眺望。
AI量价端到端策略的演进
在量价研究普遍内卷的当下,端到端建模不仅是效率的提升,亦是一种回归原始数据的研究范式。我们已实现从日频、周频等低频数据到逐笔成交、level2高频数据的全面覆盖,通过引入GRU及Transformer等架构,模型得以直接在原始数据空间中学习量价数据间的内在联系。展望未来,全频段融合或是关键,未来的端到端模型或将致力于打破时间尺度与数据形态的边界,一方面通过对比学习等技术实现多频段信息的有效融合,另一方面引入文本等多模态信息,使模型从多维信息中主动识别市场状态迁移。
AI模型的山外山与因子挖掘的分岔路口
对于AI模型而言,从广义线性模型到Transformer,我们已在传统架构中探索良久。面对模型同质化与环境漂移的挑战,未来的破局点或将在于引入先验知识与上下文感知能力,以及探索时序大模型与金融领域原生大模型的可能性。我们不仅追求预测精度,更追求模型在非平稳市场中的泛化与生存能力。对于因子挖掘,传统的遗传规划往往陷入盲目搜索的困境,而LLM的引入让因子挖掘具备了语义理解能力。未来的挖掘可能是认知型的,即利用大模型等工具在稀疏Alpha丛林中高效导航,从单一因子的发现转向因子协同与动态生命周期管理,并不执着于追求复杂公式,而是逻辑的稳健与可控。
AI量化的新世界:AI+组合优化与AI+宏观量化
与此同时,AI的应用疆域正在向策略后端与宏观顶层不断延展,开辟出全新的增量世界。AI+组合优化致力于填平预测与交易之间的鸿沟,PortfolioNet系列研究已初步实现了从收益预测到组合决策的端到端打通。未来,随着GPU并行加速技术与强化学习的结合,组合优化或将进化为能够实时响应市场变化、动态调整风险约束的智能决策系统。AI宏观量化正在经历从“解读数据”到“理解叙事”的范式转移。借助大语言模型,我们得以从海量新闻舆情中提炼宏观叙事与情绪因子,捕捉传统数据滞后的市场规律。未来,基于多智能体框架的复杂系统建模,或能让我们能够跳出线性外推的局限,在微观个体的交互涌现中预演宏观市场的起伏变化。
AI量化策略跟踪
我们对AI量化的一系列探索并非纸上谈兵,而是持续跟踪并迭代了一系列标杆策略。AI全频段量价模型自2017年以来年化超额收益显著,在样本外持续展现出对中证1000指数的稳健增强效果。Master因子与Portfolio Net 2.0通过精细化的结构设计与风格控制,既可兼顾Pure Alpha,也有机会捕获风格收益。舆情分诊台与LLM-FADT将大模型对文本的深度理解转化为交易信号,在文本另类数据相关策略中表现优异。
风险提示:通过人工智能模型构建选股策略是历史经验的总结,若市场规律改变,存在失效的可能;人工智能模型可解释程度较低,归因较困难,使用须谨慎;大模型是海量数据训练获得的产物,输出准确性可能存在风险。
正文
导读
本文是华泰人工智能系列的第100篇研究报告。自2017年6月1日发布首篇研究至以来,过往的八年半里,我们亲历了量化投资行业的这场深刻变革:
技术路径上,从早期的机器学习,演进到深度学习,再到如今以大语言模型为代表的新范式。
应用场景上,从早期的因子合成,拓展至因子挖掘与端到端建模,进而渗透到组合优化、行业轮动、资产配置、流程管理等投资的各个环节。
行业认知上,从最初的质疑与观望,逐渐转向接纳与尝试,直至今日的全面拥抱。
一路走来,我们持续探索技术创新,我们认为,先进生产力将替代传统生产力,科学方法论将替代经验主义。
第100篇研究,既是对过往足迹的回顾,也是对未来征途的眺望。立于这场技术浪潮的前沿,我们继续期待以大模型为代表的新兴技术为量化投资带来的持续变革。
AI量价端到端策略的演进
在量价研究普遍“内卷”的背景下,AI端到端建模并非仅是工程效率的提升手段,而是作为一种具备长期价值的研究范式。相较于依赖人工特征拆解、分阶段拼接的传统路径,端到端框架尝试直接面对市场原始数据,在统一的表示空间中学习价格、成交与微观结构间的内在联系。量价研究渐渐从局部经验驱动,迈向整体结构感知。
向前看,端到端量价模型的发展或将沿着更高维度的表示能力持续展开。一方面,不同时间尺度、不同数据形态之间的边界有望进一步被弱化,低频、高频至level2层面的信息或能被纳入同一学习框架之中;另一方面,模型的角色也可能从被动拟合历史规律,演进为主动识别市场微观结构模式与状态迁移规律的经验机器。在这一过程中,端到端并非终点,而是入口,其真正价值,或将体现在对Alpha生成本身的重塑之中。

AI端到端的过去与当下
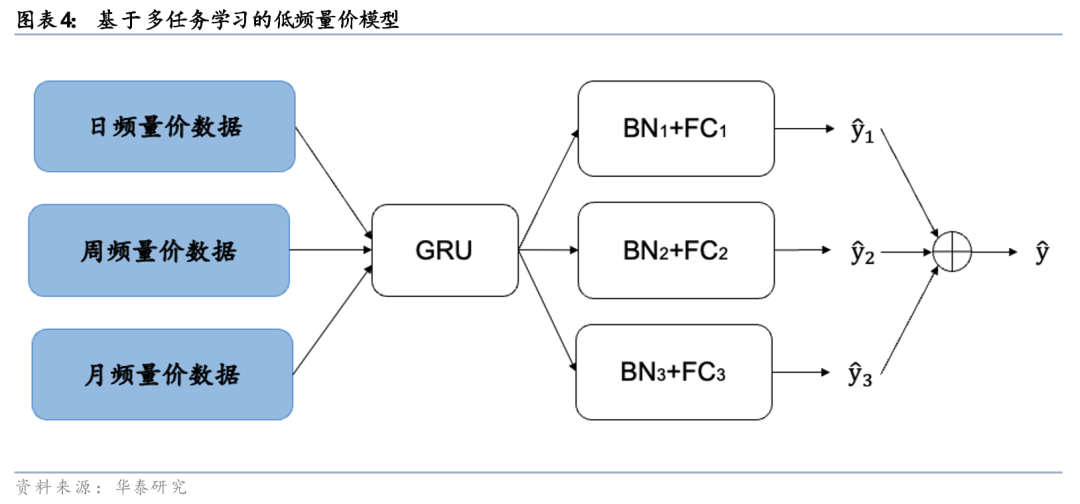
2023年5月,我们在《人工智能68:神经网络多频率因子挖掘模型》(20230511)中利用神经网络自动提取股票原始量价数据中的特征,实现端到端的因子挖掘和因子合成,成为AI量价端到端模型的开篇之作。其后,我们进一步基于多任务学习的低频量价模型,使得模型同时接收日频、周频和月频三种不同颗粒度的K线数据,采用同一个GRU模块提取时序信息、实现知识共享,从而提升合成信号的效果。
在此基础上,AI量价端到端模型的研究进一步沿着更高频、更精细的数据维度持续演进。我们逐步将建模对象由低频量价序列拓展至日内高频、逐笔成交乃至level2数据层面,围绕长序列建模、微观结构表达与信息重构等问题,引入分块(Patch)建模、注意力机制、ViT等更具表达力的深度学习范式。
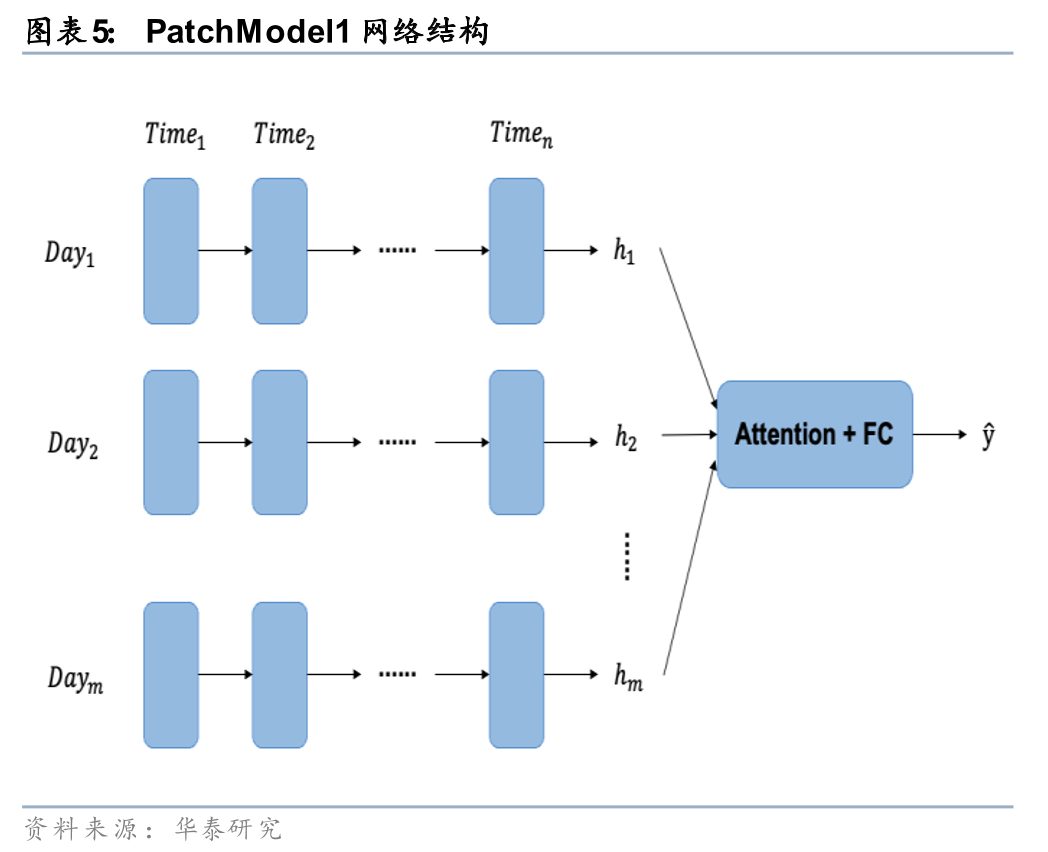
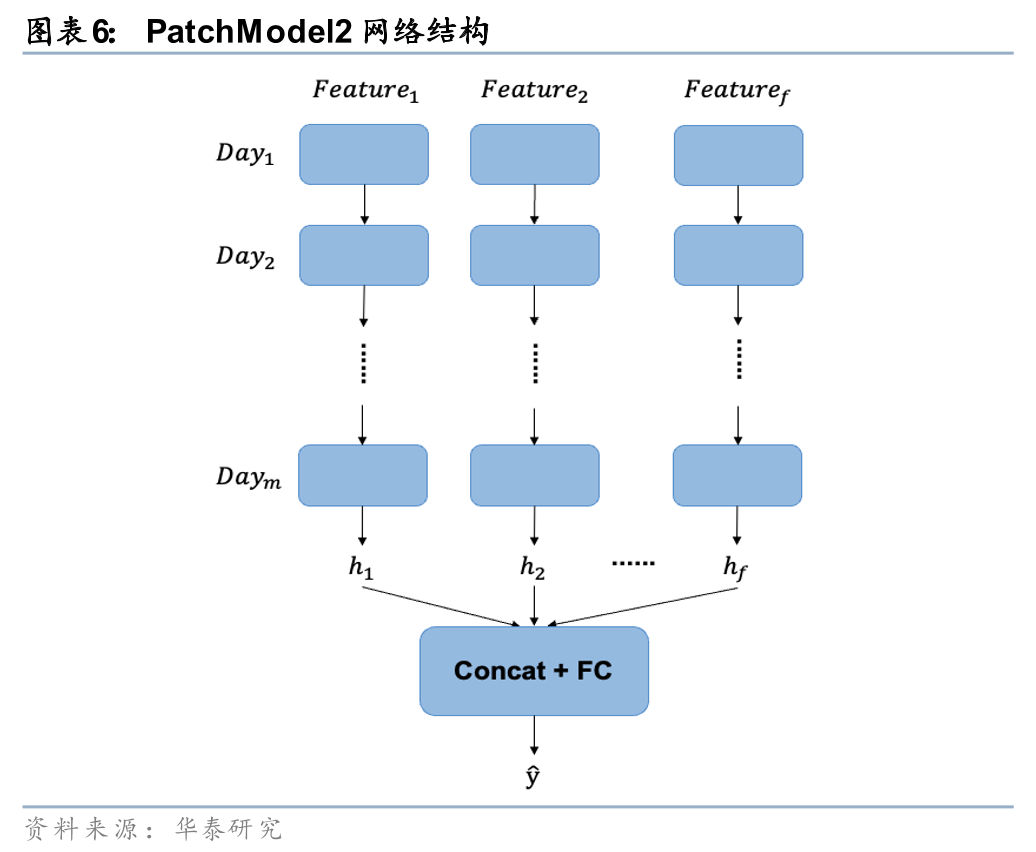
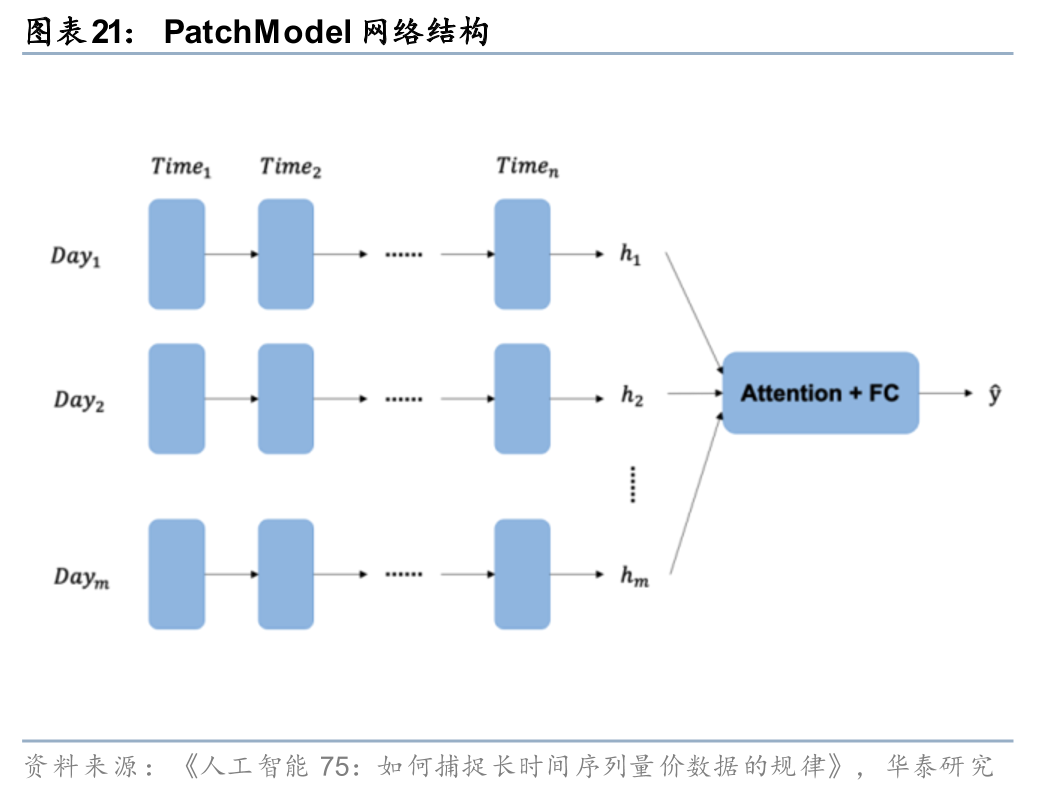
在《人工智能75:如何捕捉长时间序列量价数据的规律》(20240314)中,我们借鉴分块思想对GRU模型加以改造。按照交易日将股票的长时间序列量价数据划分为多个patch,使模型可以有效缓解信息遗忘的问题,并引入以日为周期的先验知识,差异化地分析日内和日间信息传递。PatchModel1使用GRU处理日内的时序数据,再通过注意力机制构建日间的联系;PatchModel2将日内时点信息拆解为不同的特征,再使用GRU来挖掘日间的时序规律。
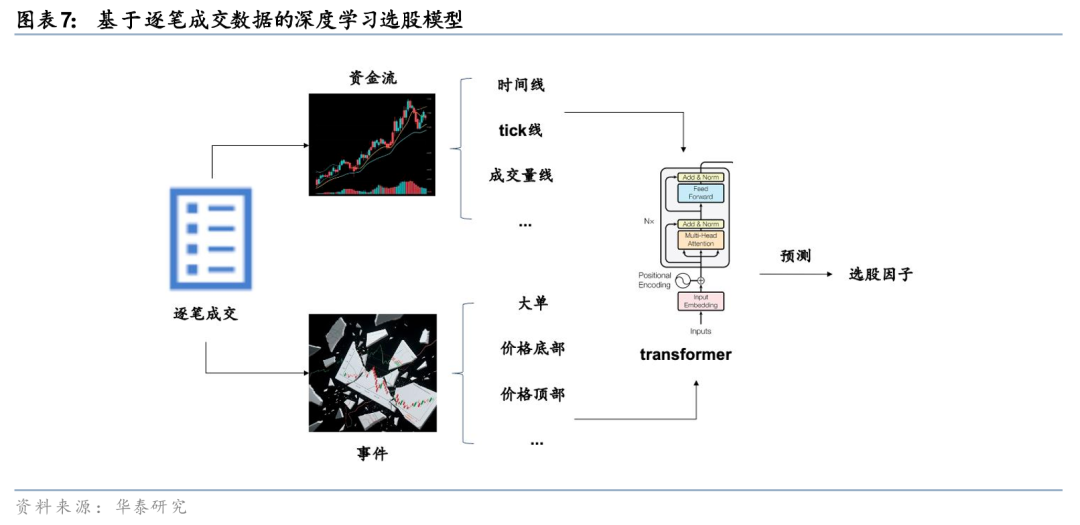
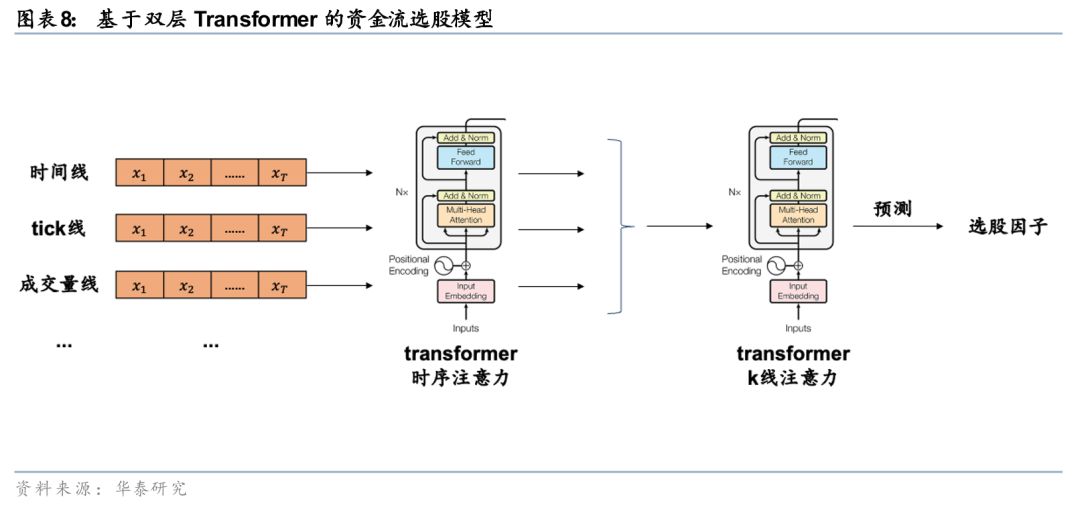
在《人工智能93:基于逐笔成交的深度学习选股模型》(20250714)中,我们构建基于逐笔成交的深度学习选股模型。我们从资金流和事件驱动两个角度开展特征工程,并利用Transformer模型学习多维度的注意力规律,最后形成有效的选股因子。以资金流模型为例,首先分别根据等时间、等成交笔数、等成交量、等价格波动,对逐笔成交数据进行采样,提取价格、成交量、大小单和主动买卖信息,形成4种结构化的K线;接着构建双层Transformer模型,第一层学习时序注意力,第二层学习跨K线注意力,最终输出个股未来10日超额收益的预测。
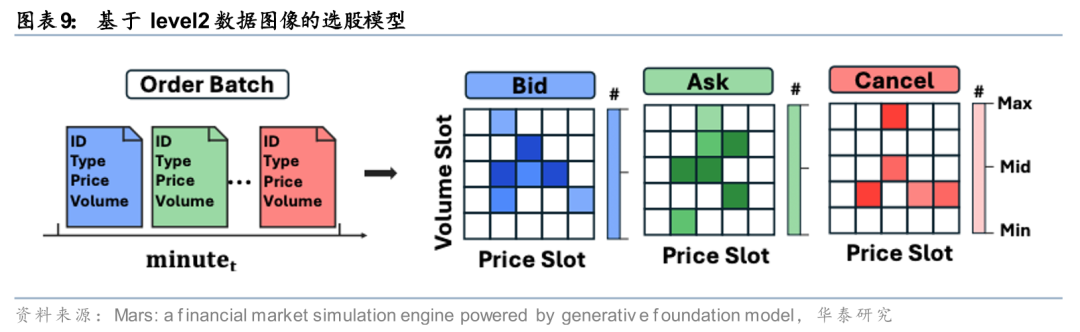
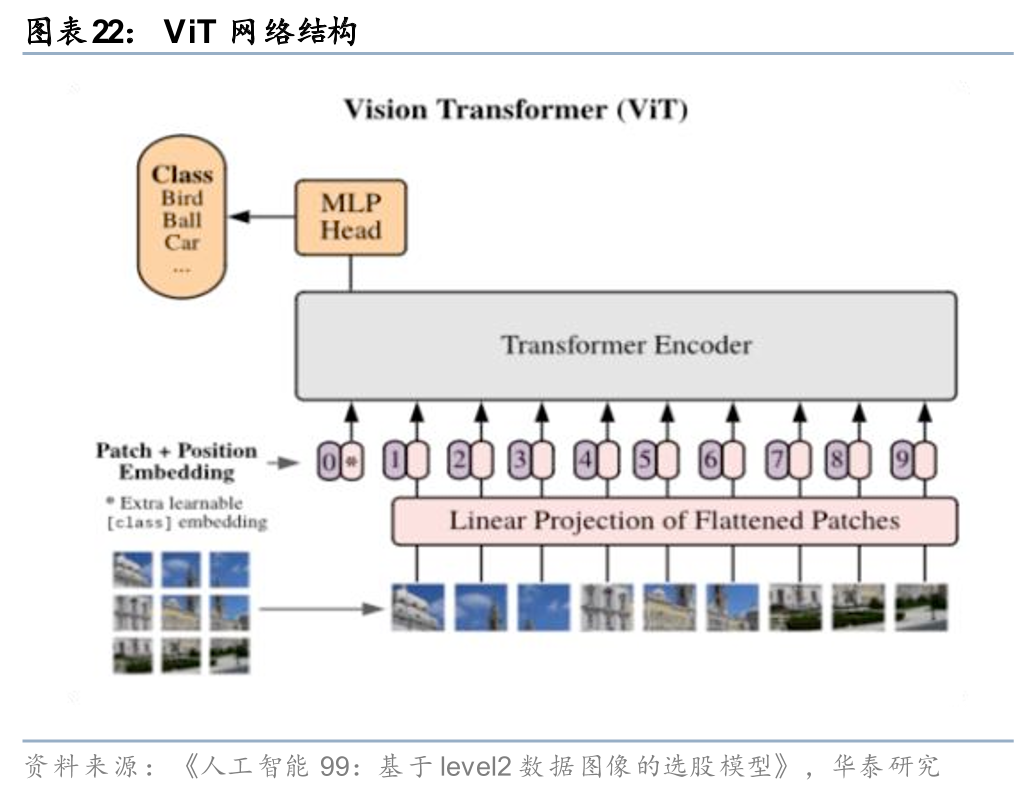
近期,我们致力于探索如何从海量level2数据中提取增量Alpha。在《人工智能99:基于level2数据图像的选股模型》(20251224)中,受微软亚研院相关研究的启发,我们提出一种基于图像识别的全新解决方案。该方法将高频逐笔成交与逐笔委托数据,转换为标准化的三维图像格式。其中,图像的通道数、宽度和高度分别对应订单类型、价格区间以及成交量/委托量区间,每个像素点的值则代表具备相同属性的订单笔数,像素值越高,表明该类订单出现的频率越高。随后,应用强大的视觉模型Vision Transformer(ViT)及视频模型Video Vision Transformer(ViViT)对生成的图像(及图像序列)进行模式识别,从中提取人工难以捕捉的微观结构信息,并最终形成个股收益预测信号。相较于前期的时序神经网络模型,本方法能够提供差异化且有效的Alpha信号。
AI端到端的未来
展望未来,我们认为全频段融合仍是未来量化研究的重要趋势,对丰富alpha来源、提升策略表现具有关键意义,可探索的方向包括但不限于:
提升对单频段数据源的表征能力
当前主要有两种思路:一是尽可能保持原始数据样貌,通过预处理使其呈现平稳分布,进而构建参数量较大的深度学习模型进行端到端学习;二是借助人工逻辑、遗传规划、大语言模型、强化学习等方法开展特征工程或因子挖掘,再采用轻量级模型进行因子合成。
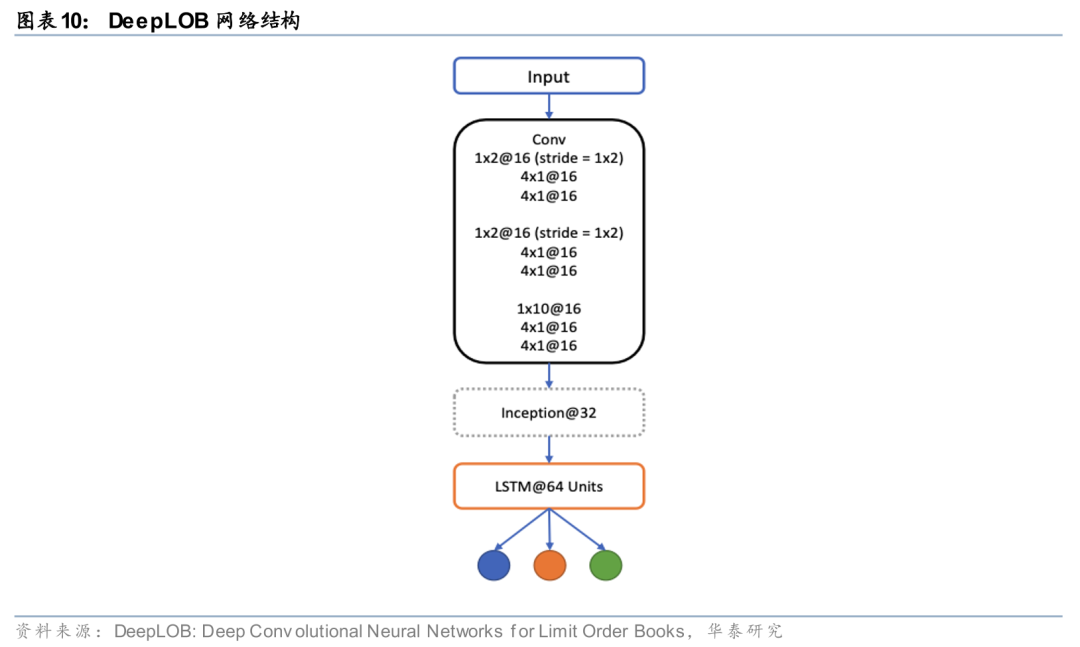
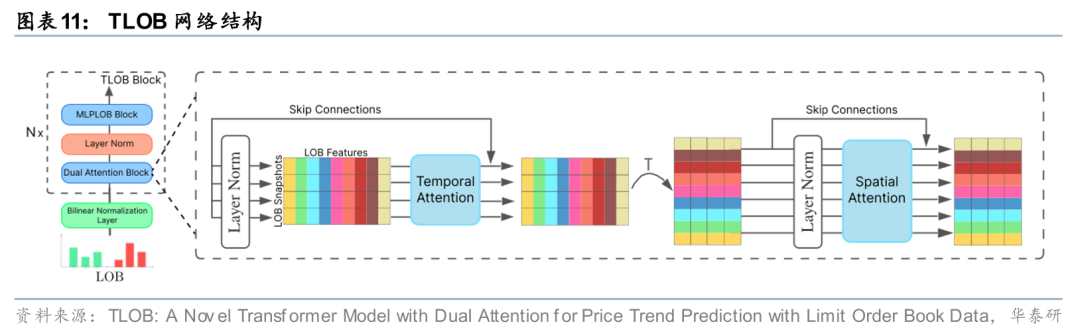
对于第一种思路,数据预处理和网络架构设计较为关键。以订单簿数据(LOB)为例,传统预处理通常采用前一日量价数据的均值和标准差对当日数据进行z-score标准化,Tran等(2020)提出双线性标准化(Biliner Normalization)方式,使模型能够自适应地学习标准化参数,从而缓解数据非平稳分布问题。在模型设计方面,Zhang等(2020)提出的经典DeepLOB模型,利用CNN捕捉价量、买卖方及档位间交互信息,并借助LSTM建模时序依赖关系;而Berti等(2025)设计的TLOB模型,通过双层Transformer同时学习时序和特征间的注意力机制,显著提升对价格趋势的预测能力。
对于第二种思路,因子挖掘将在后续章节单独讨论,对于因子挖掘而言,既需要精细化的底层字段、算子、以及挖掘流程设计,也离不开系统化的因子评价体系。例如,Ding等(2025)提出的AlphaEval值得借鉴,该框架从五个互补的维度(预测能力、时间稳定性、对市场扰动的鲁棒性、金融逻辑性和多样性)来全面评估Alpha因子的质量。
实现多频段量价信息的有效融合
目前,针对不同频段的量价数据,我们通常采取分别训练深度学习模型,而后在最终预测信号或组合层面进行融合的方式。该方法调参简单、算力需求较低,但存在各模型可能学到重复信息的不足。采用多频段量价数据联合训练,或是一条新的探索路径。
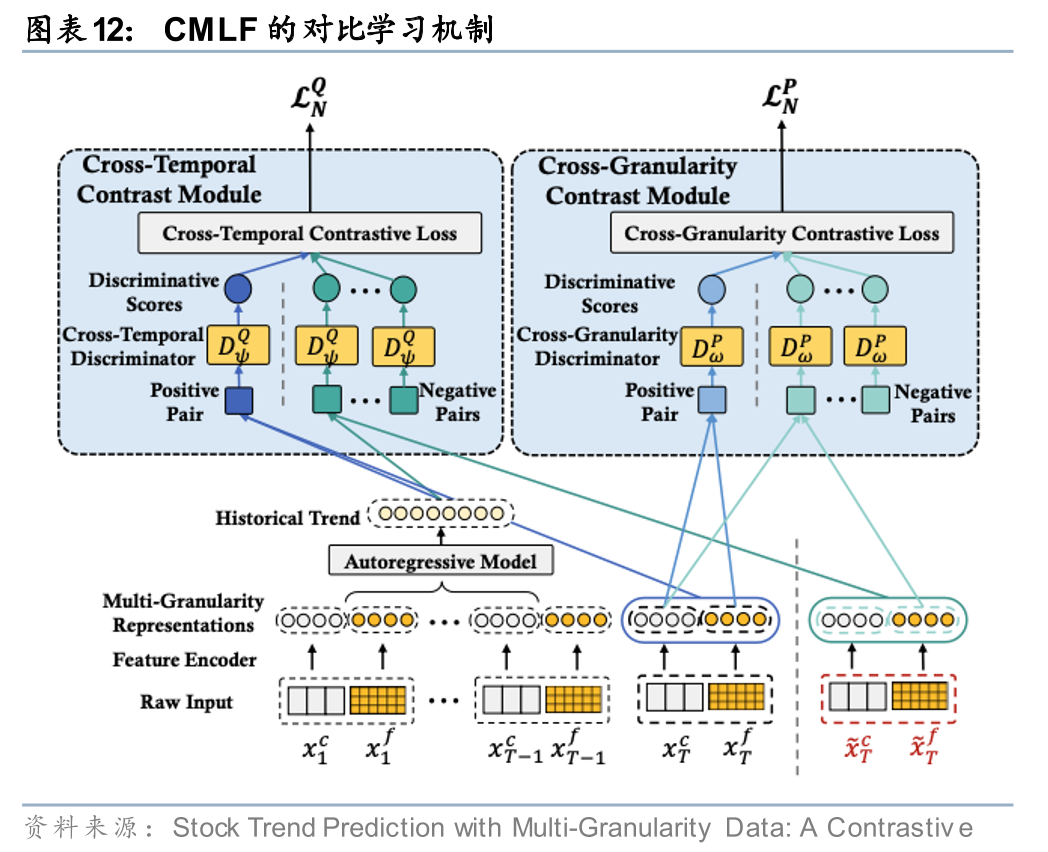
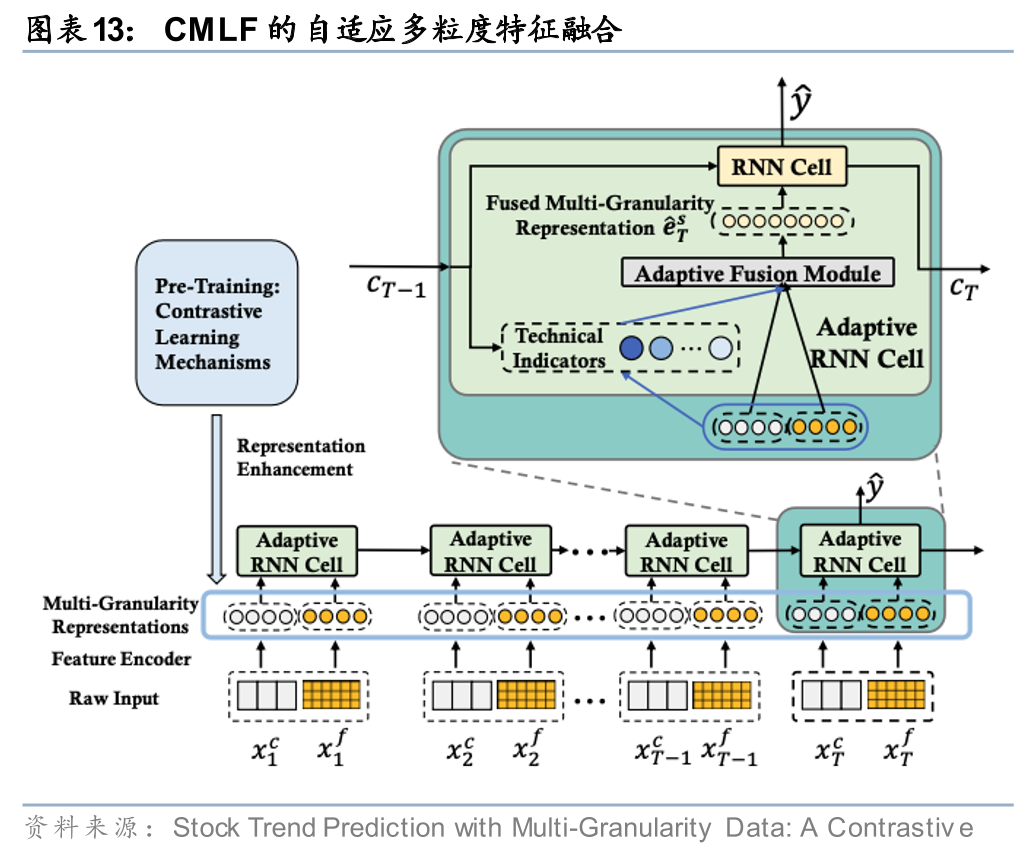
Hou等(2021)指出,直接融合不同粒度数据面临两大挑战:一是目标趋势与细粒度数据之间的粒度不一致性导致优化困难;二是金融市场状态持续变化,需要动态调整不同粒度信息的融合方式。为此,该研究提出多粒度对比学习框架(CMLF),在预训练阶段设计了跨粒度对比和跨时间对比两种机制,以学习更有效的股票表征;在特征融合阶段则引入自适应门控机制,动态调节不同粒度特征的融合权重。
Zhang等(2025)设计的多周期学习框架(MLF)包含三个核心模块:周期间冗余过滤(IRF),用于消除不同周期间的冗余信息;可学习加权集成(LWI),用于融合各周期的预测结果;多周期自适应分块(MAP),确保各周期的数据块数量一致,以降低模型偏差。
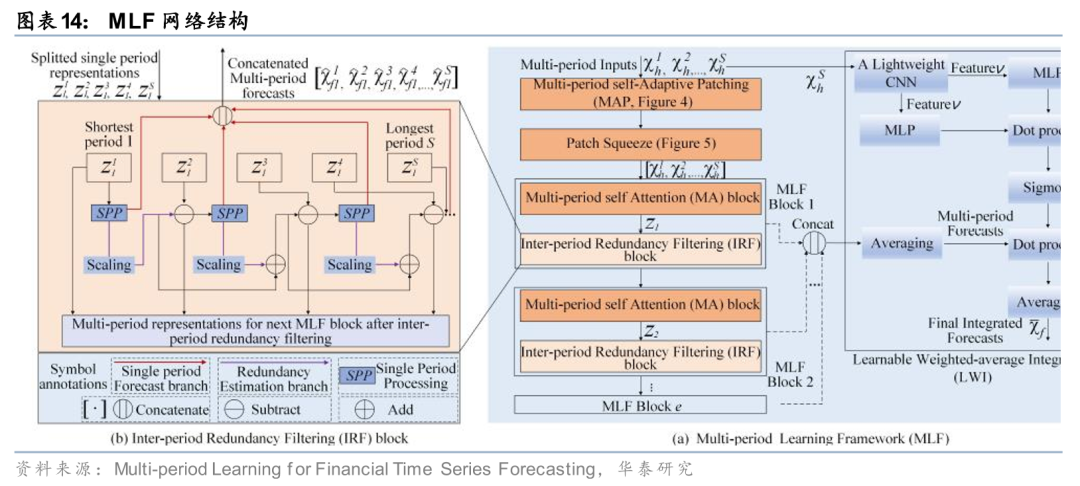
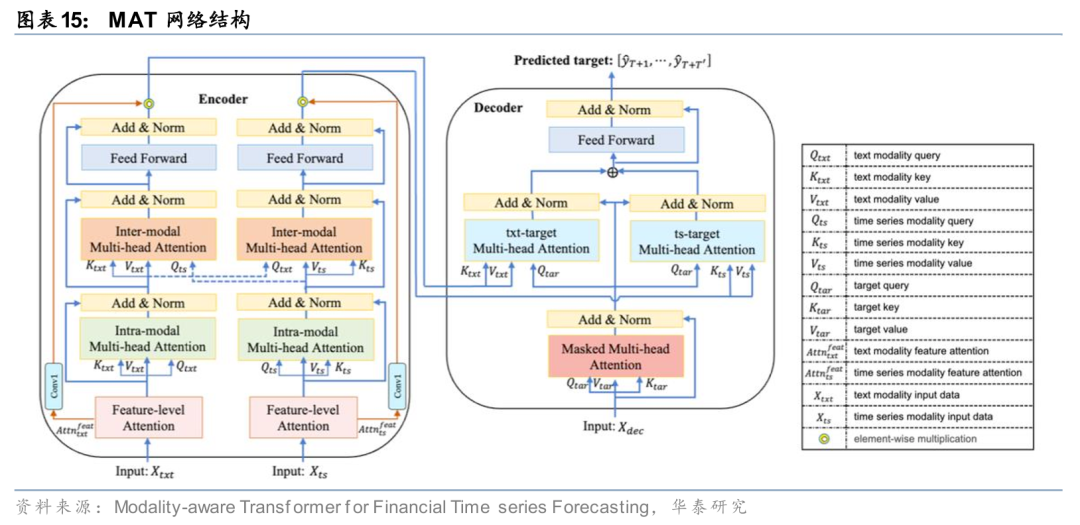
在AI量价模型中融入文本等多模态信息
当前深度学习模型在挖掘跨模态交互信息方面仍存在局限。Gohari等(2024)提出的模态感知Transformer(MAT)模型,通过引入特征级注意力层来识别各模态中最相关的特征,并设计三种多头注意力机制:模态内注意力用于捕捉单个模态内部的时间依赖关系,模态间注意力用于探索不同模态之间的关联,目标模态注意力则在解码阶段用于捕捉目标序列与各输入模态间的交互作用。
参考文献
Li, J., Liu, Y., Liu, W., Fang, S., Wang, L., Xu, C., & Bian, J. (2024). Mars: a financial market simulation engine powered by generative foundation model. arXiv preprint arXiv:2409.07486.
Zhang, Z., Zohren, S., & Roberts, S. (2019). Deeplob: Deep convolutional neural networks for limit order books. IEEE Transactions on Signal Processing, 67(11), 3001-3012.
Berti, L., & Kasneci, G. (2025). TLOB: A Novel Transformer Model with Dual Attention for Stock Price Trend Prediction with Limit Order Book Data (No. 2502.15757).
Hou, M., Xu, C., Liu, Y., Liu, W., Bian, J., Wu, L., ... & Liu, T. Y. (2021, October). Stock trend prediction with multi-granularity data: A contrastive learning approach with adaptive fusion. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (pp. 700-709).
Zhang, X., Huang, Z., Wu, Y., Lu, X., Qi, E., Chen, Y., ... & Wang, W. (2025, July). Multi-period learning for financial time series forecasting. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 (pp. 2848-2859).
Emami Gohari, H., Dang, X. H., Shah, S. Y., & Zerfos, P. (2024, November). Modality-aware Transformer for Financial Time series Forecasting. In Proceedings of the 5th ACM International Conference on AI in Finance (pp. 677-685).
AI模型的山外山
身处人工智能时代,AI模型正加速重塑量化交易的底层逻辑。随着市场AI含量的提升,传统策略生存空间或被压缩,AI间的竞争也将愈演愈烈。因此,主动拥抱AI或逐渐成为当前时代下的必然选择。本节中尝试借助团队过往研究和前沿学术文献,回顾并展望AI量化模型的过去、当下和未来,一览AI模型的演进与变迁。
AI模型的过去与当下
AI模型在量化全流程中始终占据关键地位,华泰金工在AI模型研究方面也在持续积累。回顾过往研究,从人工智能系列的开篇起,早期研究为AI模型的研究框架打下了坚实基础:除了探索XGBoost、RNN、CNN等主流AI模型结构外,还从标签、损失函数、交叉验证、模型集成等角度对AI模型在训练和应用中的细节进行全面实证测试;其后一系列研究则围绕GAN生成金融时序数据、图神经网络选股以及文本模型与另类数据的结合等核心话题展开;近期的研究则持续拥抱AI领域的新模型、新技术,探索其与量化的交界点,本节选取团队过往研究中的关键议题作简要回顾:
大模型与另类数据
另类数据中埋藏了大量尚未定价的信号,对另类数据的建模是AI量化模型的重任。华泰金工的前期研究中针对分析师研报、业绩公告、新闻等文本数据开展系列研究,利用词袋法、BERT、HAN等文本模型有效捕捉了文本数据字里行间潜藏的Alpha。
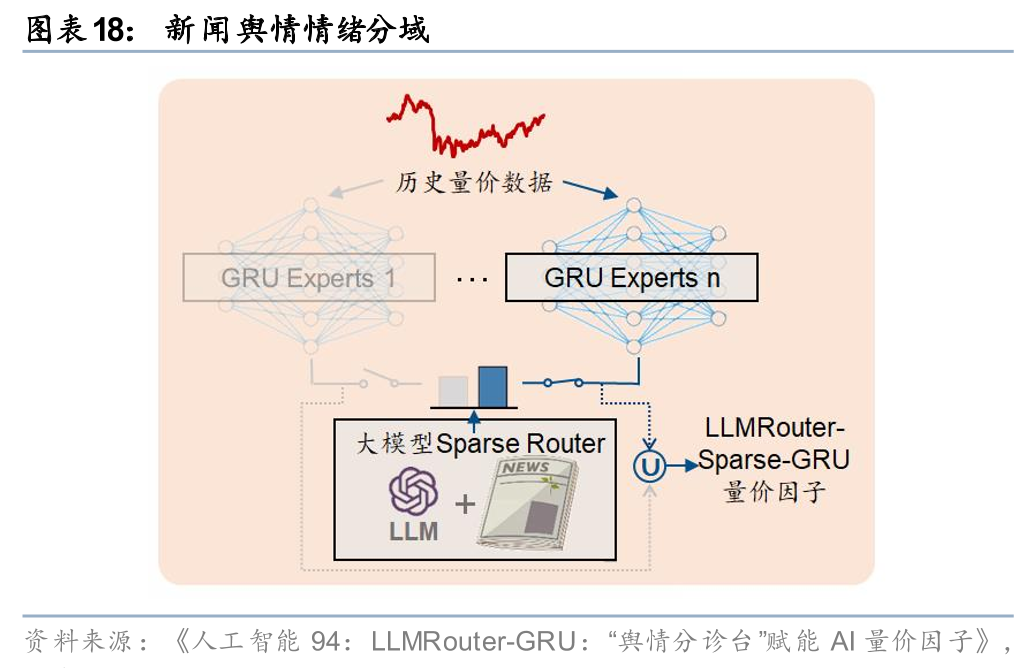
大模型的发展极大提升了另类数据的处理能力,团队近期围绕大模型与另类数据展开诸多探索。其中《人工智能92:LLM-FADT:大模型增强文本选股》(20250610)、《人工智能94:LLMRouter-GRU:“舆情分诊台”赋能AI量价因子》(20250717)借助大模型深入挖掘上市公司相关研报、新闻文本,通过数据增强、分域建模的思想将另类数据中的情绪因子与AI模型相结合。
除了与传统量化模型相结合外,《人工智能91:GPT-KLine:MCoT与技术分析》(20250530)中借助多模态推理大模型探索处理金融图像信息的能力边界,《人工智能96:LLM赋能资产配置:基于新闻数据的AI宏观因子构建与应用》(20250924)中则借助大模型处理宏观新闻事件并构建经济增长、地缘风险等宏观因子。
多变量协同建模
预测股市是一个复杂的多变量建模问题,其体现在两个方面:1、股价预测不是单变量预测问题,影响股票未来收益的特征涵盖从宏观到微观,从低频到高频的众多维度;2、市场中的每一只股票都不是独立存在的,股票与股票间通过行业、产业链、概念、风格等互相联系。因此AI模型的多变量多维度协同建模能力至关重要。
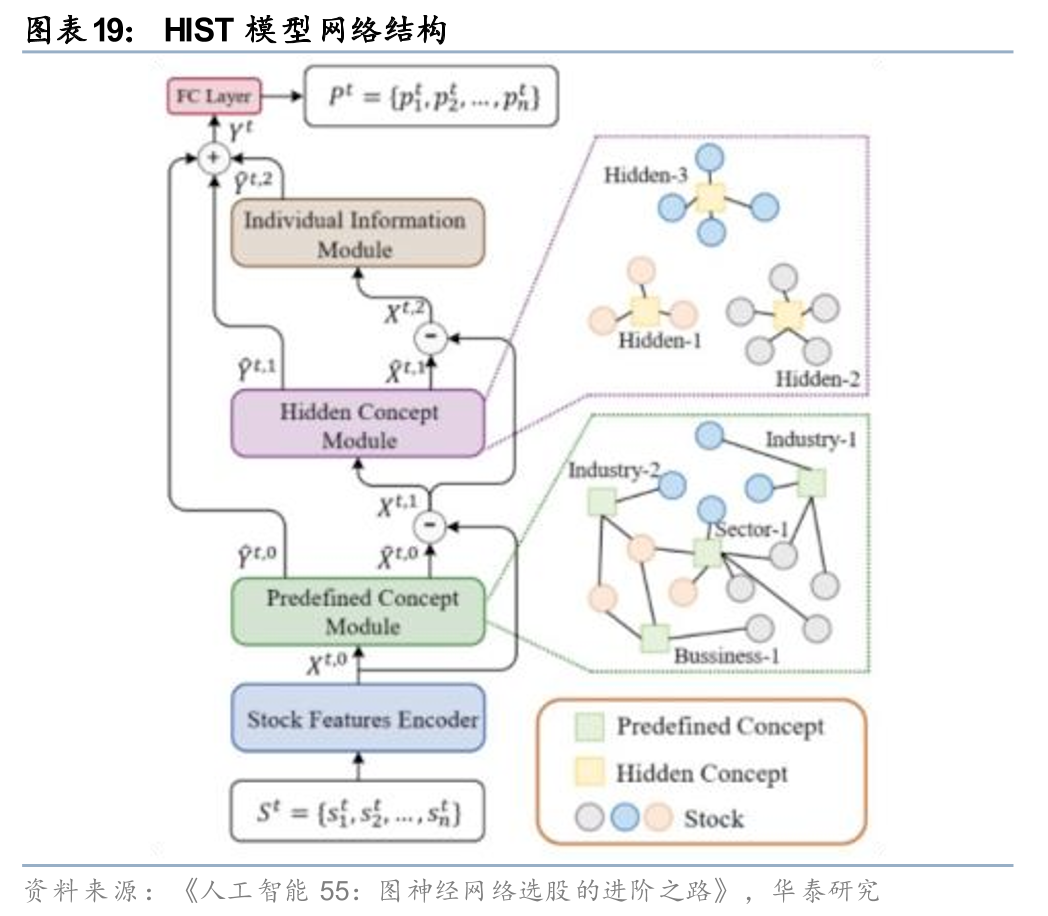
图神经网络(GNN)是多变量相关性建模的利器,华泰金工早期研究中对各类GNN模型在量化中的应用曾进行一定的探索。以HIST模型为例,在注意力机制的加持下,其通过多层残差图结构充分捕获单截面股票间显式的行业板块间关联收益、隐式的风格概念间关联收益以及剩余的股票特征性收益。
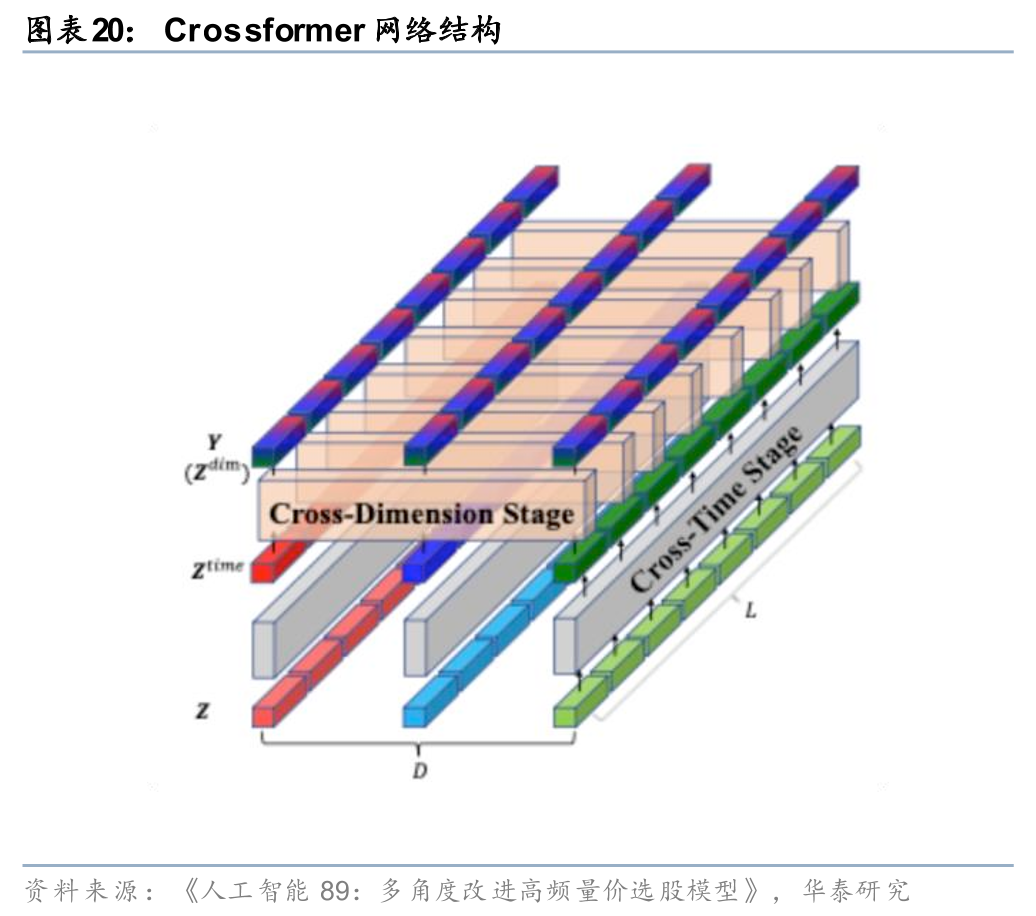
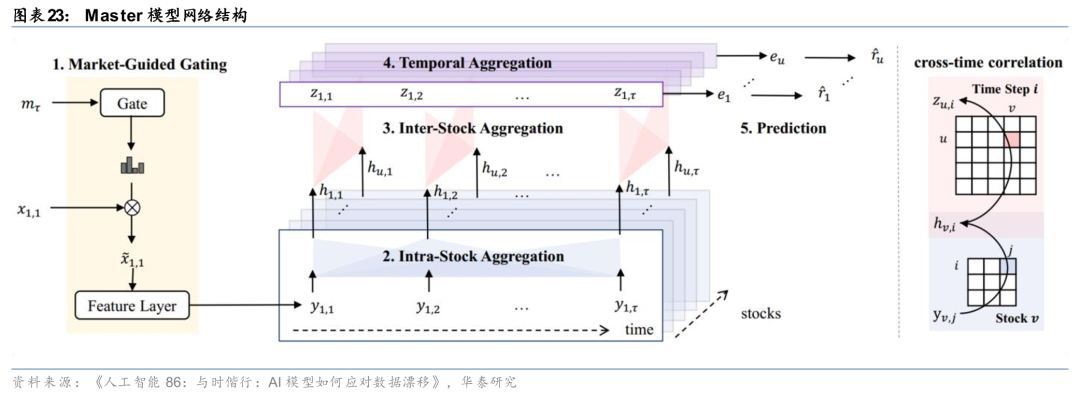
而随着Transformer的发展,注意力机制强大的关联信息提取能力使得基于Transformer架构的时序模型成为了多变量协同建模的新宠。《人工智能69:Attention is indeed all you need》(20230822)、《人工智能86:与时偕行:AI模型如何应对数据漂移》(20250221)、《人工智能89:多角度改进高频量价选股模型》(20250321)中均对基于Transformer的多变量协同建模进行探索,其底层模型结构iTransformer、Crossformer、Master等在时序注意力层的基础上通过不同方式新增了变量间注意力层,实现对股票特征在时序上、股票间、特征间的关联变化进行协同建模。
长时间序列建模
传统的深度时序神经网络在面对长时间序列时存在效率较低、信息遗忘的现象,而金融市场中的时序数据涵盖高中低频,且日内、日间不同颗粒度信息分布不均匀,对长时间序列的合理建模的重要性更加凸显。团队近期研究中针对该问题亦尝试多种方案应对:
其中,《人工智能75:如何捕捉长时间序列量价数据的规律》(20240314)中借鉴PatchTST时间序列分块建模的思想,对股票量价数据按照交易日进行分块,并在时序、特征两个维度利用GRU进行建模,有效缓解GRU模型信息遗忘的问题,同时还可引入以日为周期的先验知识,差异化地分析日内和日间信息传递。
当数据频率从分钟频进一步提升至逐笔订单级别,此前介绍的《人工智能99:基于level2数据图像的选股模型》(20251224)则尝试将长时间序列的level2数据图像化,并利用同为分块建模思想的ViT(Vision Transformer)等模型进行建模,保留长时间尺度下level2数据的局部特征和不同时点、不同日期下市场微观结构变化的整体特征。
增强模型泛化性
股票收益预测问题面临的核心挑战之一为股票市场的非平稳性,因此提升AI量化模型的泛化性能也是重要研究方向。华泰金工以往研究中针对该问题做过多角度尝试:
《人工智能67:AI模型如何一箭多雕:多任务学习》(20230506)和《人工智能78:多任务学习选股模型的改进》(20240506)的解决方案为多任务学习。通过在模型训练时引入多项预测目标,使得模型从“专才”转变为“通才”,不再局限于单目标的极致优化而落入过拟合的陷阱。
《人工智能84:SAM:提升AI量化模型的泛化性能》(20241010)和《人工智能86:与时偕行:AI模型如何应对数据漂移》(20250221)则分别从神经网络的鲁棒优化器和为模型引入先验知识的角度,提升模型在样本内外表现的稳定性,或让模型能根据市场特征变化进行动态自适应调整。
AI模型的未来
展望未来,AI模型还有哪些方向隐含较大发展潜力?还有哪些难题亟待攻克?本节通过以下几个开放式问题,尝试勾勒出AI量化模型发展前景的大致轮廓:
大模型重塑传统AI量化模型的可能性?
大语言模型的飞速发展已悄然改变了众多金融量化场景中的投研范式,典型应用场景如金融文本建模、智能投研助手、因子挖掘、辅助编程等。而对于以“拟合过去、预测未来”为目标的传统AI量化模型,大模型的技术路线是否仍能走通?时序大模型或是可行的途径之一。时间序列数据可以看作一种多模态数据,想将大模型平移至时序预测任务,其首先需要掌握“时间序列数据”这一特定语言。
如何将大模型的能力圈拓展至时序数据的预测任务?大致可分为两种流派:其一为通过微调、提示词工程、语义对齐等方式,在现有基座模型的基础上强化大模型对时间序列数据的感知和理解,使其具有预测时序未来变化的能力,如Zhou等(2023)GPT4TS、Jin等(2024)TimeLLM等;其二为基于海量的通用时序数据样本从头训练时序领域专精的基座大模型,如Google Research等Das等(2024)发布的TimesFM,AWS AI的Ansari等(2024)发布的Chronos等。
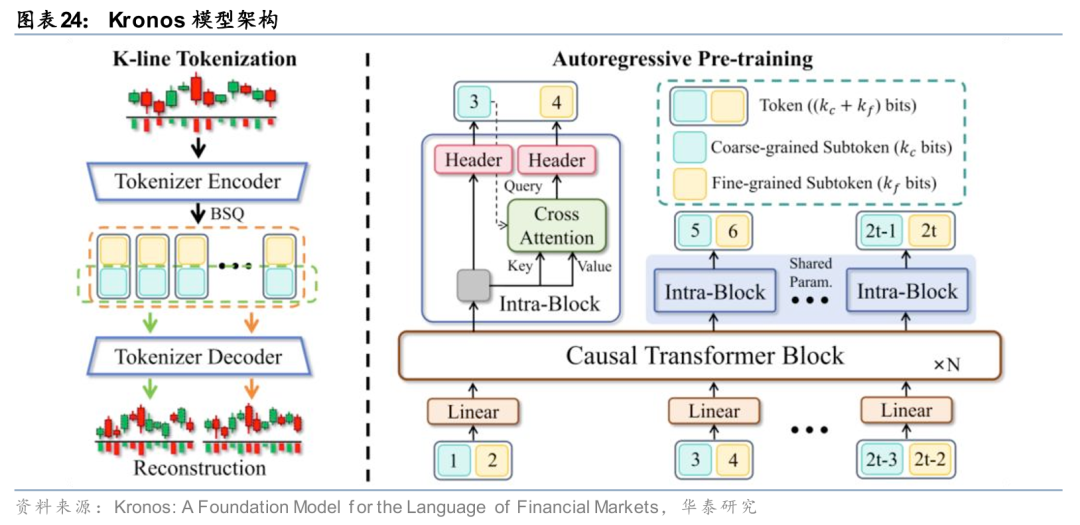
然而,基于通用数据训练的时序大模型显然无法胜任股票预测任务,因此基于金融领域原生数据的预训练或微调是必然选项。Shi等(2025)基于全球数十个市场、多频率的百亿量级K线数据,训练基座模型Kronos,是对金融市场领域原生大模型的有意义探索之一。
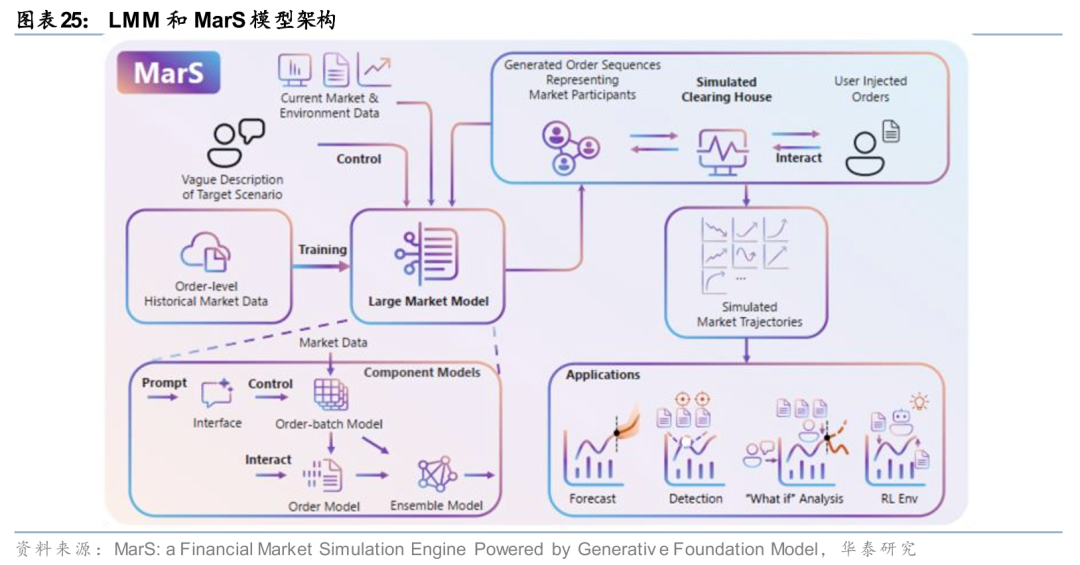
深入挖掘高频数据或是另一可行思路。Nagy等(2023)的研究、Wheeler和Varner(2024)提出的MarketGPT和Li等(2025)提出的LMM、MarS等模型均做过不同程度的探索,核心在于将市场自上而下解构至每一笔订单和交易,训练大模型学习最细颗粒度的市场微观结构,再自下而上进行重塑,训练一个金融市场领域原生的“世界模型”。这样,数据质量和数量不足、数据特异性和模型通用性矛盾、市场信息建模特征单一等问题均有望得到缓解。
另类数据与AI模型未来的结合方式?
大模型的发展极大拓展了AI量化策略的数据来源且提升了另类数据的可用性,其与AI量化策略的结合方式也将更加丰富。
一方面,对于文本模态的另类数据,从公司财务报告、公告,到分析师研报,再到新闻舆情和社交媒体言论,利用大语言模型的汇总、推理能力进行深入挖掘,并探索文本数据多样化的“变现方式”,仍有丰富想象空间。
另一方面,随着大模型的能力边界从自然语言处理拓展至多模态任务,多模态数据的语义对齐和融合建模或许也是利用另类数据的另一种思路。以Qin等(2025)的研究为例,其构建CoRA模型对新闻文本、图像与传统金融时间序列数据进行协同建模。其中多模态的信息分别经各自领域的基座模型提取隐含表征,再经由格兰杰因果嵌入模块建立不同模态间的联系。
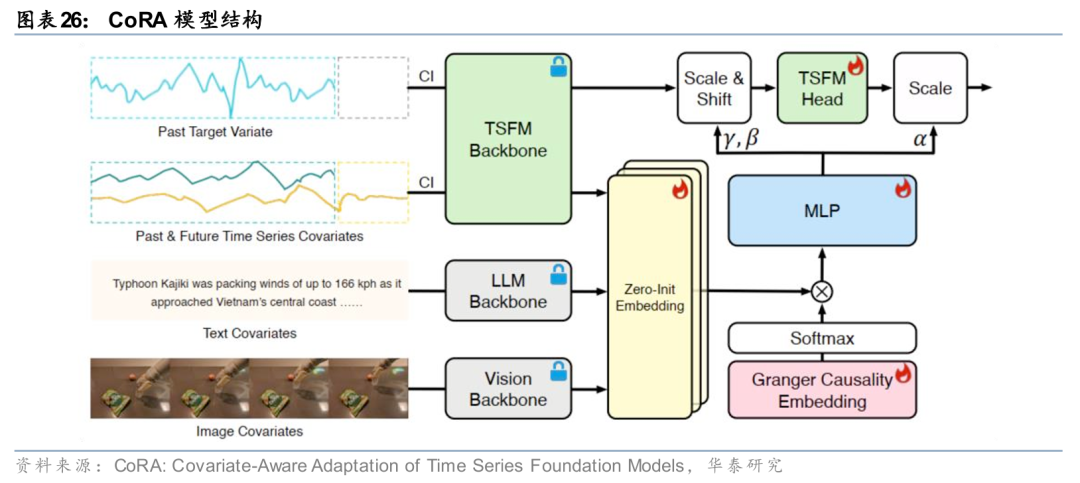
新模型结构是否值得尝试?
人工智能领域对于深度学习模型底层结构的创新从未停止,而应用于量化投资的AI模型中,XGBoost、RNN、Transformer等成为绝对主流,量化领域似乎已进入运用AI模型的舒适圈。那么,新模型结构是否还有尝试的意义?我们认为,至少以下三点原因或可说明新模型仍值得探索:
1、 特征建模的差异化:通过不同的模型架构捕捉数据中的差异化特征,或可为量化策略提供低相关性收益来源;同时,将不同模型结构有机结合形成混合架构,或可起到取长补短的效果。
2、 突破模型效率瓶颈:当AI模型用于处理海量高频时间序列数据,对模型训练、推理速度的限制提出更高要求,基于Mamba等线性复杂度模型结构或可有效应对。
3、 提升模型可解释性:KAN或符号回归等新型模型架构在构建之初就具备结构上的透明度,将其与AI量化模型有效结合或可从模型底层揭秘AI量化的“黑箱”。
AI量化模型是否会失效,又该如何应对?
当历史无法推演未来,AI量化模型将面临失效。而市场永远充满变数,因此AI量化模型的失效似乎是必然的。深入拆解,导致AI量化模型失效的原因或可总结为以下几点:
1、 流动性陷阱:策略同质化将导致市场中量化参与者交易信号趋同,而随着AI在量化策略中的渗透率不断提升,在有限的流动性下,相似模型捕捉到的超额收益将持续衰减直至消失。
2、 市场环境漂移:AI模型本质上是通过历史数据寻找规律。当市场环境受参与者结构、宏观政策、地缘风险、投资者情绪等场外因素影响而发生“漂移”,基于历史样本训练的模型将面临失效风险。
3、 极致风格:AI模型的超额=能力机会。纵使模型本身较强,若失去获取超额的环境也将无能为力。当市场进入低波动或者低离散的状态,流动性过度集中于个别主题或风格,AI模型学习到的统计规律也就无从施展。
4、 极端风险:AI模型所挖掘的可能是不显著成立的统计规律,和海量历史数据中隐含的微薄超额收益。当遭遇尾部风险,AI模型所追求的稳定Alpha或难以维持。
当然,合理的应对方法或可有效缓解AI模型失效的问题。除了完善风控体系、持续迭代因子和模型、多策略配置等手段,AI模型层面的针对性改进同样重要,从学术界有关AI模型鲁棒性、泛化性的研究中或许可获得一定启发,本节从中挑选三种思路的典例简要介绍:
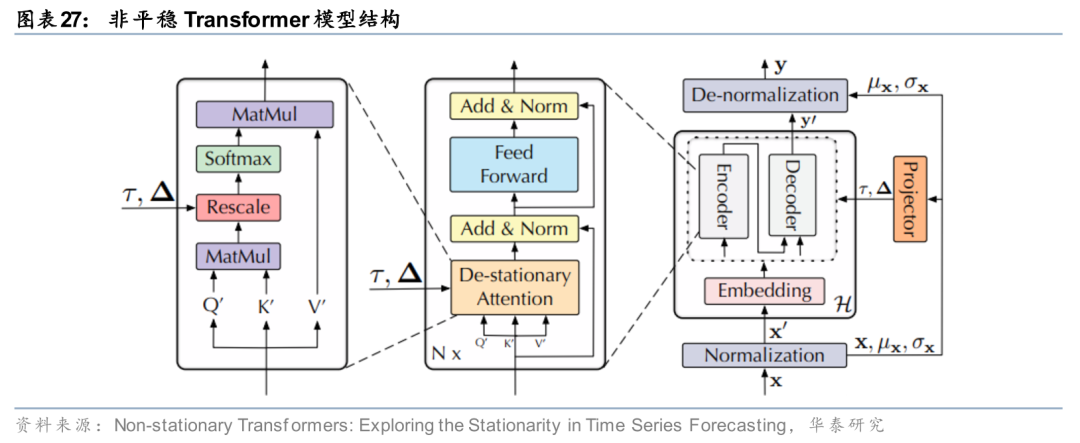
思路一:针对数据分布的自适应调整。训练AI模型时的常规步骤是对输入数据进行标准化预处理,如在时序维度作Z-Score标准化或均值中心化,其实已将时间序列中的非平稳信息过滤,或将丢失一部分关键信息,例如股价波动水平、股价历史分位数等。因此Liu等(2022)对Transformer的底层架构进行改造,首先保留数据预处理时描述原始数据分布特征的参数(如均值、方差等),再将注意力机制中计算的自注意力权重按照从原始数据分布特征中学习得到的平稳因子进行放缩,将数据分布的统计特征引入注意力特征提取模块中,从而使模型能感知到数据分布的变化。
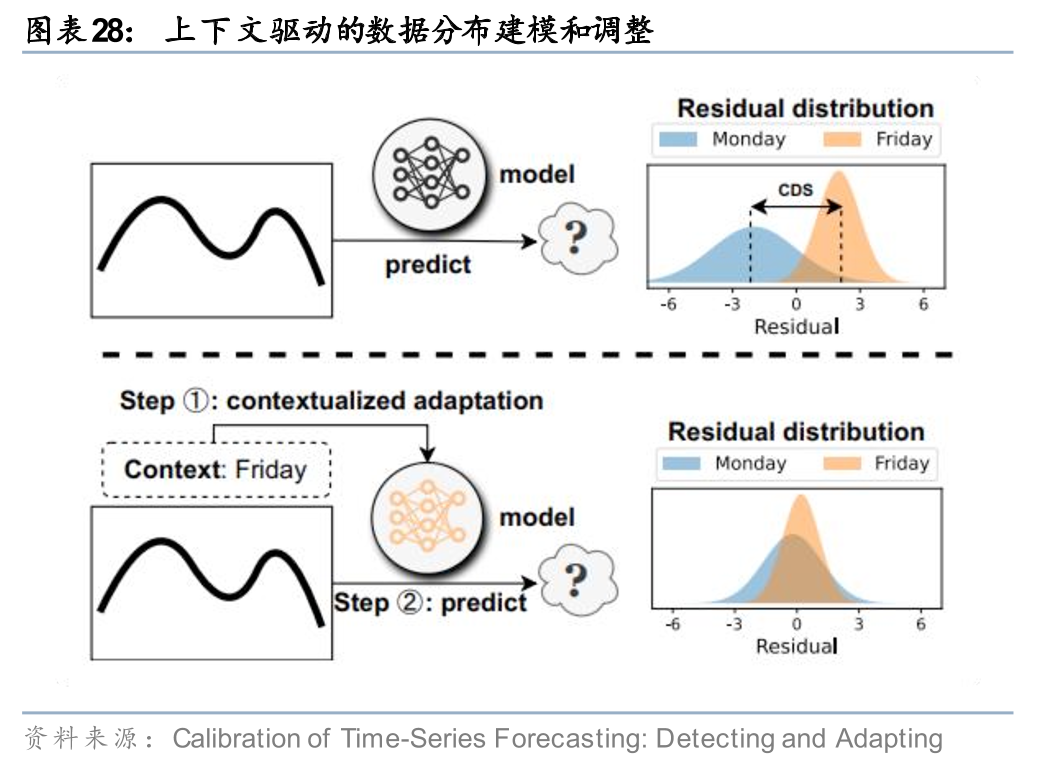
思路二:引入先验信息,建模和预测市场环境变化。除了被动的适应数据分布的变化,另一个思路是对数据的变化进行主动的建模和预测。以Chen等(2024)的模型为例,其假设时序数据分布受某些上下文语境的影响,例如周一和周五的数据分布存在某种潜在的差异。因此其为模型引入了一个前置模块,专对特定上下文语境下的数据分布进行建模,在该模块的帮助下,预测模块工作时即可根据特定语境自适应调整。股票市场同样存在各种各样的“上下文语境”,如宏观周期、日历效应等,该研究中基于上下文的数据分布建模方式或许对于金融市场的时序分域建模有一定启发。
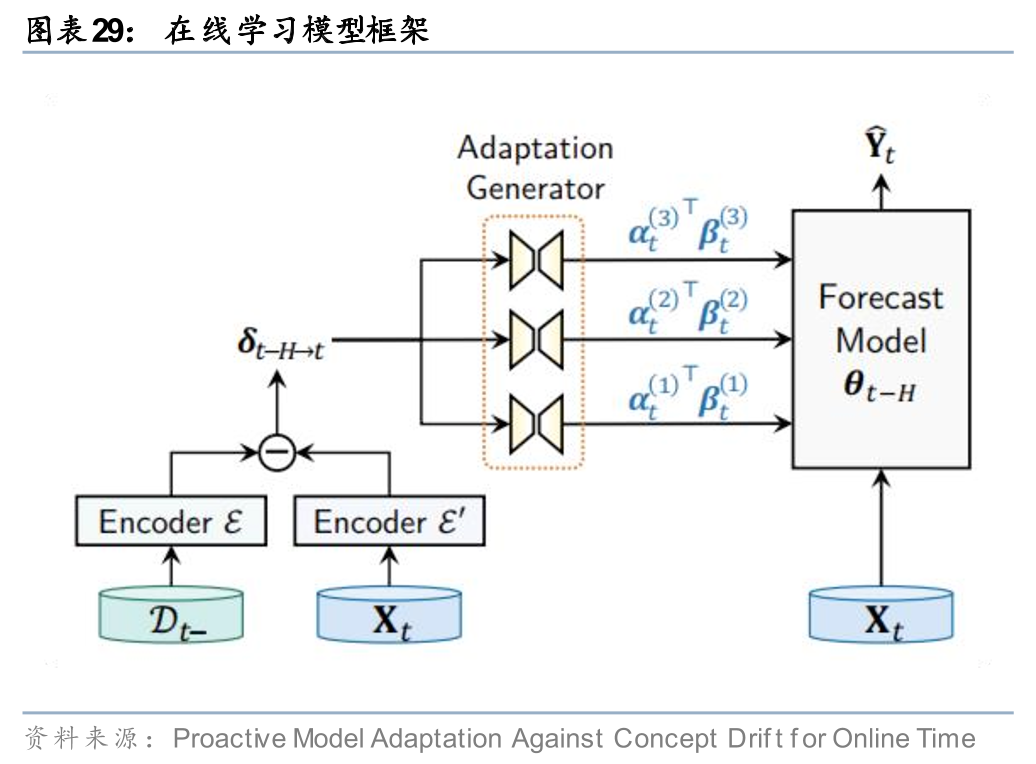
思路三:提升模型迭代速度。静态的模型无法学习动态的市场,因此提升模型泛化性更直接的思路是提升模型的迭代速度,在线学习、元学习或强化学习等训练技巧均起到类似效果。以Zhao和Shen(2024)对Online Time Series Forecasting的研究为例,其提出的在线学习框架通过一组编码器对时序数据分布的偏移进行建模,并将其映射至模型权重空间,从而实现在推理时根据数据集分布变化在线调整模型权重。
参考文献
Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., Zschiegner, J., Maddix, D. C., Wang, H., Mahoney, M. W., Torkkola, K., Wilson, A. G., Bohlke-Schneider, M., & Wang, Y. (2024). Chronos: Learning the Language of Time Series
Chen, M., Shen, L., Fu, H., Li, Z., Sun, J., & Liu, C. (2024). Calibration of Time-Series Forecasting: Detecting and Adapting Context-Driven Distribution Shift. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 341–352.
Das, A., Kong, W., Sen, R., & Zhou, Y. (2024). A decoder-only foundation model for time-series forecasting
Jin, M., Wang, S., Ma, L., Chu, Z., Zhang, J. Y., Shi, X., Chen, P.-Y., Liang, Y., Li, Y.-F., Pan, S., & Wen, Q. (2024). Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Li, J., Liu, Y., Liu, W., Fang, S., Wang, L., Xu, C., & Bian, J. (2025). MarS: A Financial Market Simulation Engine Powered by Generative Foundation Model
Li, T., Liu, Z., Shen, Y., Wang, X., Chen, H., & Huang, S. (2024). MASTER: Market-Guided Stock Transformer for Stock Price Forecasting. Proceedings of the AAAI Conference on Artificial Intelligence, 38(1), Article 1.
Liu, Y., Wu, H., Wang, J., & Long, M. (2022). Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting. Advances in Neural Information Processing Systems, 35, 9881–9893.
Nagy, P., Frey, S., Sapora, S., Li, K., Calinescu, A., Zohren, S., & Foerster, J. (2023). Generative AI for End-to-End Limit Order Book Modelling: A Token-Level Autoregressive Generative Model of Message Flow Using a Deep State Space Network
Qin, G., Chen, Z., Liu, Y., Shi, Z., Liu, H., Huang, X., Wang, J., & Long, M. (2025). CoRA: Covariate-Aware Adaptation of Time Series Foundation Models
Shi, Y., Fu, Z., Chen, S., Zhao, B., Xu, W., Zhang, C., & Li, J. (2025, August 2). Kronos: A Foundation Model for the Language of Financial Markets.
Wheeler, A., & Varner, J. D. (2024). MarketGPT: Developing a Pre-trained transformer (GPT) for Modeling Financial Time Series
Zhao, L., & Shen, Y. (2024). Proactive Model Adaptation Against Concept Drift for Online Time Series Forecasting
Zhou, T., Niu, P., Wang, X., Sun, L., & Jin, R. (2023). One Fits All:Power General Time Series Analysis by Pretrained LM
因子挖掘的分岔路口
过去十余年,因子挖掘技术路径从人工构造、遗传规划、神经网络、强化学习挖掘到大模型生成不断演进,搜索空间不断扩大,表达能力持续增强,模型愈发具备人类能力。与此同时,可解释性下降、稳定性不足、过拟合风险、跨市场失效等问题不断显化,我们不得不重新审视,什么样的因子才是可被长期持有的Alpha?
一个可能的答案是,因子并非越复杂越好,而因子挖掘技术需要在表达能力、搜索效率、经济含义、稳健性之间不断寻找新的平衡点。

因子挖掘的过去与当下
在我们的人工智能系列研究中,因子挖掘相关研究也在不断探索和积累。人工智能21《基于遗传规划的选股因子挖掘》(20190610)是因子挖掘研究的起点,此后历经遗传规划的改进与泛化、AlphaNet因子挖掘神经网络、大模型因子挖掘、强化学习因子挖掘。我们聚焦于搜索机制与模型结构层面的可能性验证,为因子挖掘的自动化与规模化奠定方法基础。
其中,因子挖掘范式的转变之一,可能发生在大语言模型的引入时刻。相较以往依赖既定算子空间与奖励函数的算法体系,大模型在因子挖掘中首次具备了对金融语义与逻辑结构的整体理解能力,自动化因子挖掘不再局限于形式上可计算,逐渐开始向逻辑上可解释迈进。
在此基础上,我们进一步探索大模型与强化学习的融合路径,以强化学习承担高维表达式空间中的序列化搜索任务,由大模型提供知识约束与方向引导,从而在搜索效率、因子质量与稳定性之间取得更优平衡。当下阶段的研究,或已不再是对单一方法的尝试,而是对可能具有长期生命力的因子挖掘体系展开的完整探索。
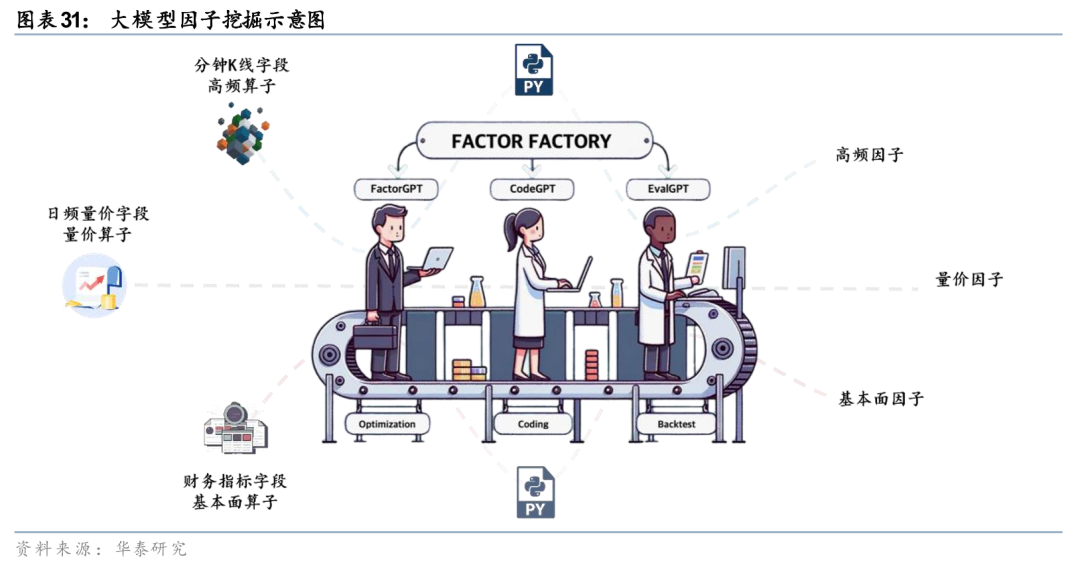
因子挖掘的未来
风险因子挖掘
相较于传统的收益因子挖掘,风险因子挖掘或将成为崭新的方向,后者关注不确定性的结构与变化,而非收益本身。传统风险因子多依赖人工设定或统计提取,能够刻画主要风险来源,但在高频数据、多状态切换与非线性环境下,传统方法对风险形态的刻画逐渐显得粗糙。随着市场结构复杂化,风险因子研究的核心问题可能是如何在保持经济含义清晰的同时,更细致地刻画波动、相关性与尾部风险等风险结构特征。
近期已有研究尝试将Transformer引入风险因子挖掘(Xu et al., 2025),HRFT(High-Frequency Risk Factor Transformer)作为一种端到端的挖掘框架,将符号数学类比为语言,利用Transformer强大的序列建模能力,直接从高频交易特征中自动提取可解释的公式化风险因子。该模型通过混合词表同步预测因子逻辑与常数,能够精准度量短期市场收益分布的方差,从而捕捉传统方法难以刻画的非线性波动规律。
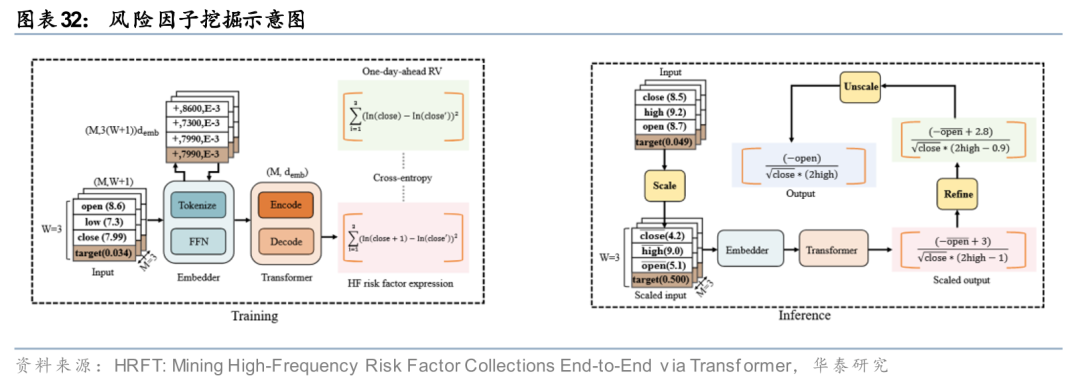
从应用视角看,风险因子挖掘的关键一方面在于风险维度的丰富,另一方面也在于形成可持续迭代的风险因子集合,使风险识别、监控与替换成为一个稳定运转的过程。
LLM驱动的因子语义进化
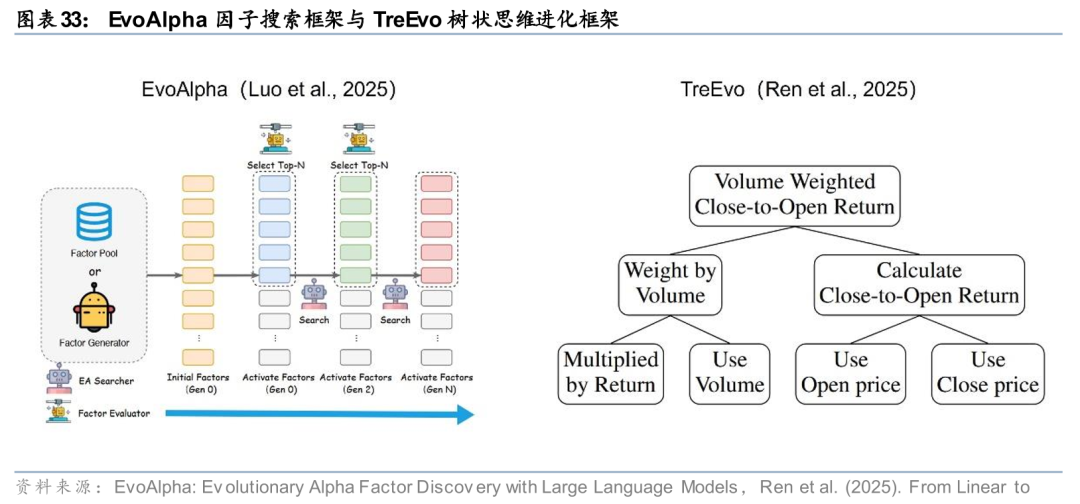
传统的遗传规划在因子挖掘中常面临盲目搜索的困境,即变异和交叉操作缺乏语义理解,导致大量产生无效或冗余的公式。展望未来,基于大语言模型的“认知型”挖掘将成为核心范式。不同于简单的代码生成,这一方向强调将LLM作为具有推理能力的“认知智能体”(Cognitive Agent),利用其对代码逻辑和金融语义的理解来指导进化过程(Liu et al., 2025; Ren et al., 2025)。
最新的研究如TreEvo(Ren et al., 2025)和CogAlpha(Liu et al., 2025)展示了这一趋势的潜力。TreEvo引入了“树状思维进化”(Tree-structured Thought Evolution)的概念,不再仅仅是在代码字符层面进行变异,而是在“思维链”(Chain of Thought)层面进行推演。模型能够像人类研究员一样,先构建分层的交易逻辑(如动量、反转的组合逻辑),再将其转化为具体代码。这种从线性代码生成向层次化思维进化的转变,不仅大幅提升了搜索效率,还保证了挖掘出的因子具有更好的可解释性和逻辑鲁棒性。
Alpha稀疏丛林与挖掘效率
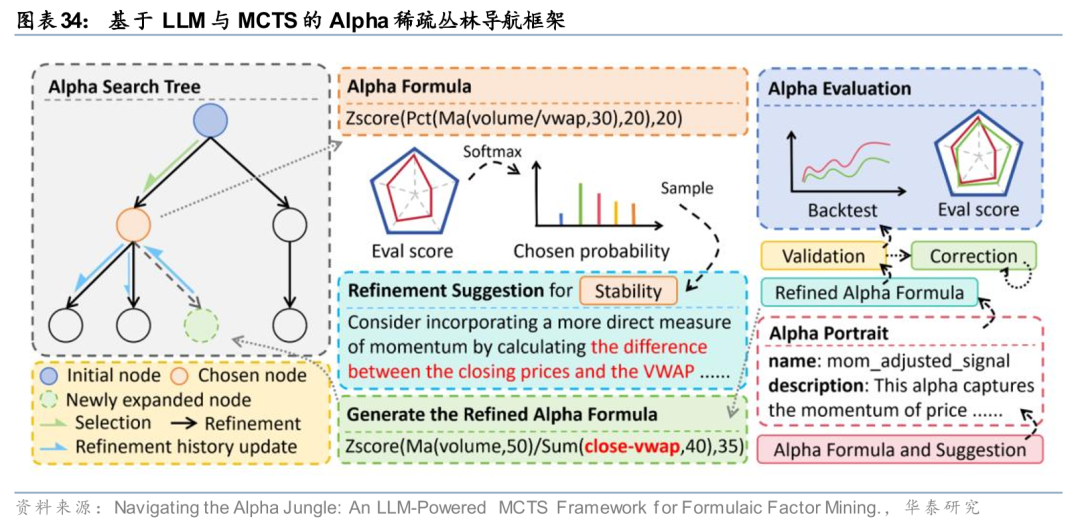
在大语言模型赋予因子挖掘认知能力的同时,如何在高维稀疏的Alpha丛林中高效导航,仍是一个巨大的挑战。传统的随机搜索或贪心策略容易迷失方向,而未来的挖掘引擎将更多融合蒙特卡洛树搜索(MCTS)等规划算法,通过构建决策树,算法能够前瞻性地评估每一步算子选择的长期价值,而非短视地追求当前收益。
前沿研究如Alpha Jungle(Shi et al., 2025)展示了这一方向的可行性。该框架将LLM的生成能力与MCTS的规划能力相结合,LLM作为策略网络(Policy Network)提出候选公式,而回测结果则作为价值网络(Value Network)的反馈信号。进一步的,RiskMiner(Ren et al., 2024)提出了一种“风险寻求”(Risk-Seeking)的MCTS变体,专门用于探索那些位于搜索空间边缘、虽然风险较高但潜藏着较大超额收益的稀有因子。这种有规划、有策略的搜索范式,可能会提升因子挖掘的效率。
因子协同与动态组合
单纯追求单个因子的IC或夏普比率或已逐渐触及天花板,未来的因子挖掘重心可能会转向“因子协同”与“动态组合”。AlphaForge(Shi et al., 2025)和Synergistic Alpha(Shin et al., 2024)等研究表明,下一代挖掘框架将不再是孤立地生产因子,而是直接面向投资组合的最终表现进行端到端的优化。
具体而言,AlphaForge提出了一种动态的因子合成与更新机制。它不仅挖掘基础公式,还通过基因拼接(Gene-splicing)等算子寻找能与现有因子库产生正交贡献的新因子。更重要的是,这类框架引入了动态权重调整机制,能够实现基于市场环境变化实时重组因子。这种从单枪匹马到协同进化的转变,可能会使得多因子体系利用大量弱信号构建出强健的综合因子,有效应对市场风格的快速切换。
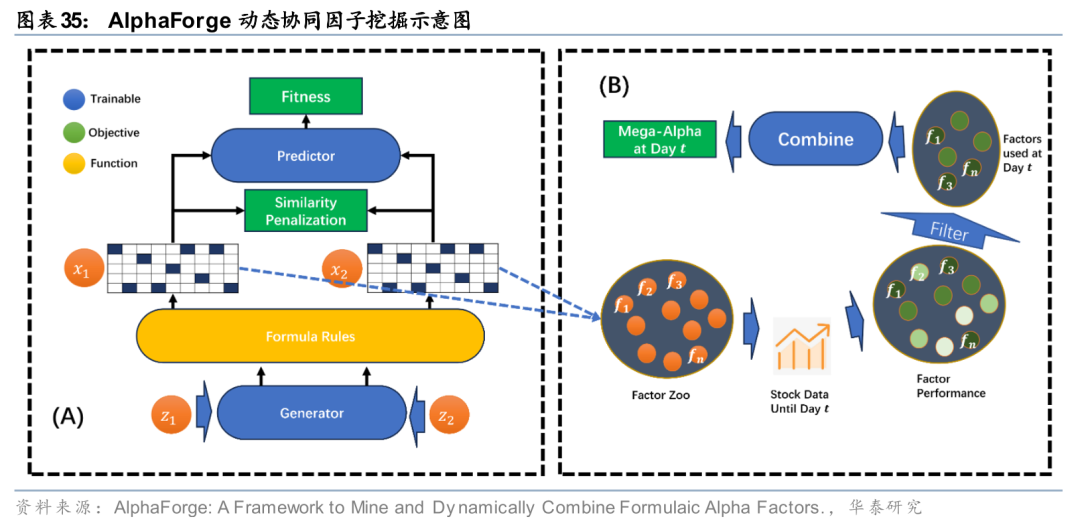
不是更复杂,而是更可控
过去十余年的因子挖掘往往在不断扩张表达空间,不断地追求能生成多少种可能性,但我们认为,未来的重心或许会转向一个更工程化也更长期主义的方向,即如何让因子从诞生开始就处在可监控、可进化、可替换的生命周期管理之中。
这背后的逻辑并不复杂——市场的非平稳性决定了任何Alpha都天然面对衰减困境,差别只在于我们能否尽早识别衰减、解释衰减、并以最低成本完成替换与再平衡。与其把因子挖掘视作一次性发现,不如将它视作持续的终生管理闭环,这里包括但不限于模型如何自动识别因子失效、因子失效后选择丢弃还是优化、市场风格切换时如何更新因子池等等。未来量化因子的胜负手,可能不在因子数量,而在于因子挖掘体系的生命力。
参考文献
Xu, W., Wang, R., Li, C., Hu, Y., & Lu, Z. (2025, May). HRFT: Mining High-Frequency Risk Factor Collections End-to-End via Transformer. In Companion Proceedings of the ACM on Web Conference 2025 (pp. 538-547).
Luo, H., Ko, H. T., Sun, D., Zhang, Y., & Liu, C. EvoAlpha: Evolutionary Alpha Factor Discovery with Large Language Models.
Ren, J., Zhao, J., Liu, S., & Yang, P. (2025). From Linear to Hierarchical: Evolving Tree-structured Thoughts for Efficient Alpha Mining. arXiv preprint arXiv:2508.16334.
Shi, Y., Duan, Y., & Li, J. (2025). Navigating the Alpha Jungle: An LLM-Powered MCTS Framework for Formulaic Factor Mining. arXiv preprint arXiv:2505.11122.
Shi, H., Song, W., Zhang, X., Shi, J., Luo, C., Ao, X., ... & Seco, L. A. (2025, April). Alphaforge: A framework to mine and dynamically combine formulaic alpha factors. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 39, No. 12, pp. 12524-12532).
AI+组合优化的天堑变通途
AI在Alpha预测领域的应用已趋于成熟,然而策略实战中或会出现“优质因子难出优质组合”的困境:因子本身具备优秀的预测性能,但经风险约束传导、组合优化器处理后,最终组合的收益风险表现可能存在偏差。其核心症结在于,因子挖掘的核心目标(如最大化IC)与组合优化的收益(Mean)—风险(Variance)目标存在内在冲突,这种冲突会非线性放大部分预测误差,导致组合配置方案偏离真正的最优解。下文将梳理团队针对上述问题的部分研究成果,同时展望AI+组合优化的未来探索方向,探寻如何打通收益预测到组合决策的关键链路。

AI+组合优化的过去与当下
AI+组合优化的重要落地场景在于“端到端”,即尽量在AI预测股票收益的环节,便将组合约束考虑在内。实践中,如果缺失了这一环节,便可能导致因子挖掘与组合优化“各自为政”,挖掘出的因子存在风格暴露隐患。AI模型仅关注信号强弱,因子信号无法实现理想的风格剥离,Pure Alpha收益受到侵蚀,进而导致组合波动加大、回撤风险上升。
基于这一观点,团队持续推进AI+组合优化的融合研究,形成了以PortfolioNet系列模型为核心的研究成果,下面开展简要回顾。
早先,在前期研报《神经网络组合优化初探》(20220109)中,我们就曾运用cvxpylayers 开展了将神经网络组合优化应用于资产配置的探索。随后,研究报告《PortfolioNet: 神经网络求解组合优化》(20241031)将前述场景由资产配置扩展至选股,模型前端基于量价数据生成信号,随后经过新型的可微优化层LinSAT投影为合规的组合权重,组合收益直接参与损失计算并反向传播,从而实现由“原始数据输入”至“投资组合输出”的一站式建模。
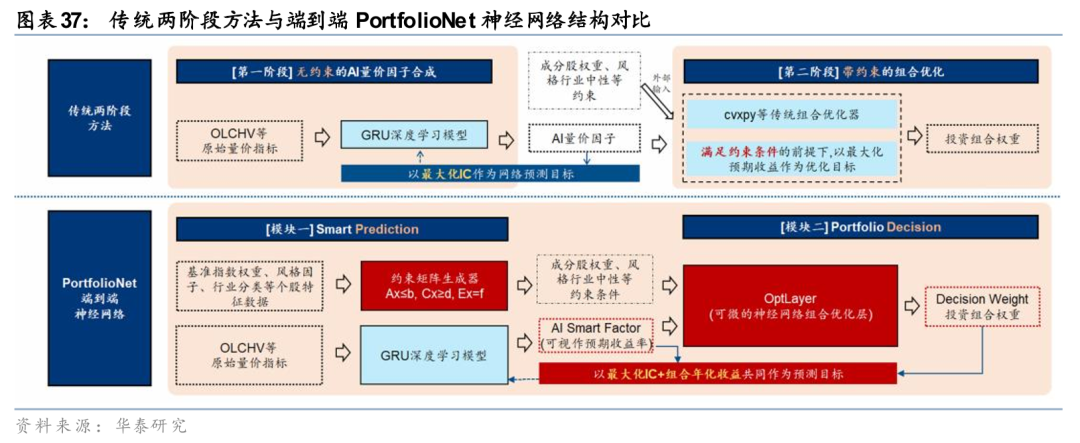
在此基础上,后续研报关注到端到端组合优化面临的另一问题——AIpha信号无法实现理想的风格剥离,Pure Alpha收益受到侵蚀。针对该问题,《PortfolioNet 2.0:如何兼取风格收益与 Pure Alpha》(20251216)在前期模型之上,对组合约束项赋予可微性能,让AI 量价因子追求较高收益弹性,捕捉 Pure Alpha 之外的风格收益。在回测区间2023-01-03至2025-11-28内,合成因子相比于经典AI量价模型取得明显提升,在300增强、500增强与1000增强场景下,年化超额收益分别提升7.5pct、7.5pct与8.5pct,信息比率同步改善。
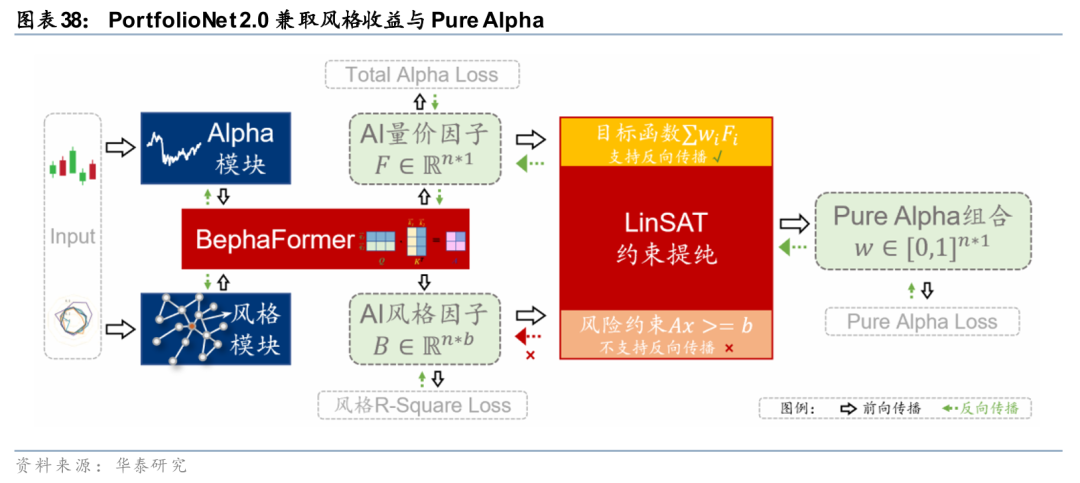
以上两项研究从不同角度推动了AI+组合优化的落地:前者着眼于打通预测与优化的断层,使模型直接对组合决策结果负责;后者则利用AI组合优化算法,巧妙地从原始Alpha信号中剥离出Pure Alpha组合,使模型兼取Pure Alpha与风格收益。相关方法与实验结果已在前期研报中作了更为系统的展开,本文仅作问题脉络与研究线索的简要梳理,以供参考。
AI+组合优化的未来
以PortfolioNet系列为代表的AI+组合优化策略可帮助因子信号与组合决策“牵线搭桥”,但若放眼整个投资流程,组合优化中仍有大量环节处于“半手动”状态。当前的研究与实践,大多仍着眼于收益预测或单一优化问题,而在如何智能设定约束、动态反映风险偏好、高效求解以及升级决策机制本身等方面,进展依然有限。
现实中,组合优化从来都不是一道静态的数学题——它随着市场环境、客户需求与交易规则持续演化。因此,AI 组合优化的潜力远不止“更准的决策”,更在于更快的求解、更聪明的约束、更灵活的风险表达,并将这些环节整合成一个能够持续学习、自主迭代的智能系统。
从这个视角出发,AI+组合优化仍有广阔天地值得探索。下文将从两个方向展开:
1. 优化器与算法端的改进——提升大规模、多约束下的求解效率与稳健性;
2. 强化学习与大模型在组合优化中的应用——拓展动态、自适应决策的新范式。
优化器与算法的改进
在指数增强或全市场选股等场景下,组合优化往往需要在数千只股票中同时处理权重决策与多重约束,目标函数与约束矩阵维度极高,计算量随之迅速增大。近期,为克服组合优化“路径依赖”、“日历效应”等扰动,部分投资者会选择多个组合优化初始点取路径平均,在此类大规模计算场景下,传统组合优化方法常因求解效率不足而难以胜任。因此,如何在保证数值稳定性的前提下提升大规模组合问题的求解效率,成为影响算法落地的重要瓶颈。
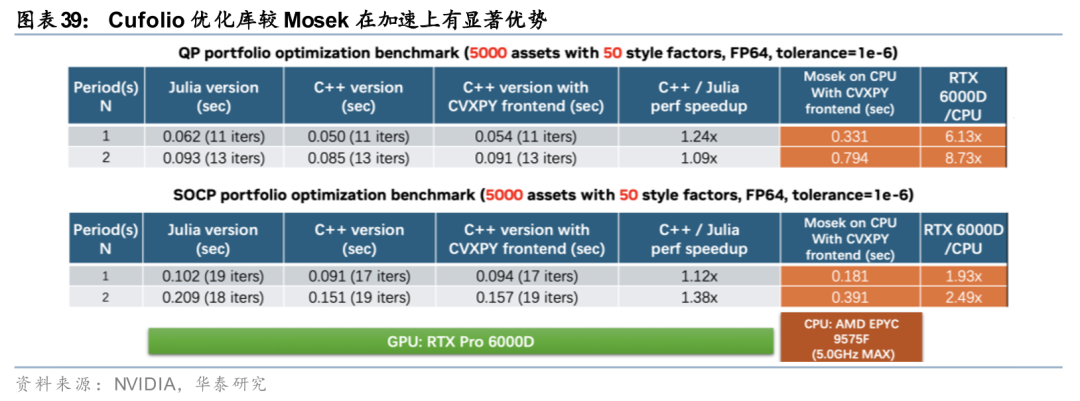
近年来,研究和工程实践开始关注组合优化求解器的加速,在并行化实现、GPU原生计算以及结构化矩阵运算等方向已取得多项可落地的技术成果。例如英伟达推出的cuFolio组合优化库,尝试将经典组合优化问题映射至GPU架构下高效求解,为大规模、多约束组合优化提供了可行的工程化加速路径。这类底层算力与算法实现的进展,为组合模型在实际投资场景中的应用打开了新的空间。
另一方面,在端到端组合优化框架中,引入可微优化层是实现信号学习与组合决策协同优化的关键步骤。但前期研究使用的LinSAT可微优化层采用投影式求解,在保证梯度可传播的同时牺牲了一定的最优性。如何在高维组合场景下平衡计算效率与解的精度,提升可微优化层输出结果的质量与稳定性,也是值得持续探索的方向。
强化学习/大模型+组合优化
强化学习的引入,为组合优化问题提供了新的建模视角。不同于传统优化对单期目标的强调,强化学习以长期累计回报为核心,将权重调整本身视为一条随时间展开的决策路径,从而在一个统一框架下同时考虑收益、风险与调仓行为。这种思路使组合优化不再只是连续求解静态问题,而是直接学习“如何在变化的市场中行动”。
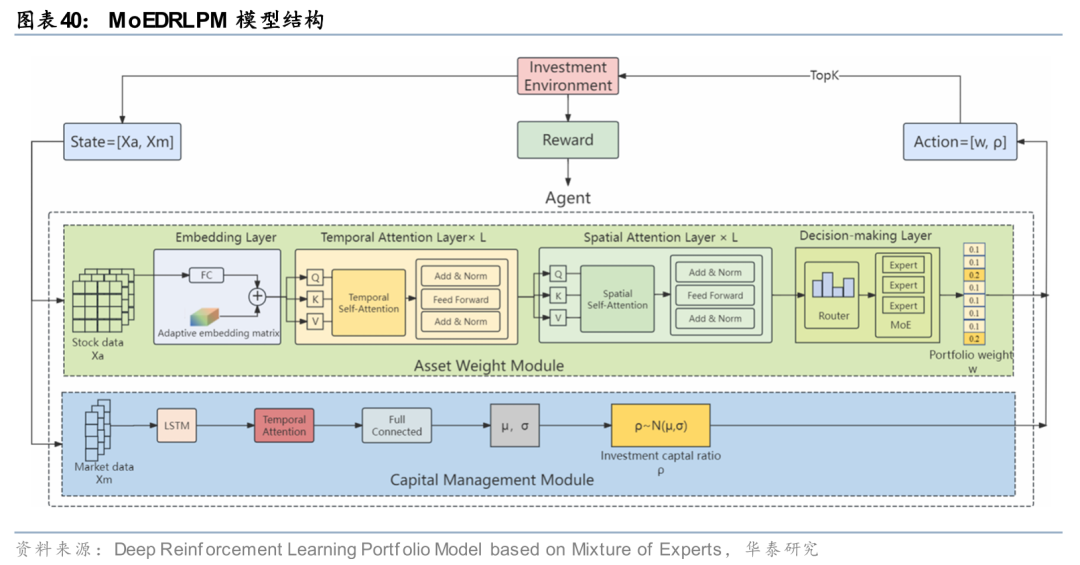
近期研究显示,强化学习在投资组合中的作用正在从简单的权重生成,向更具结构性的决策范式演进。Wei 等人(2025)提出的MoEDRLPM(Deep Reinforcement Learning Portfolio Model based on Mixture of Experts),通过引入时序与空间注意力机制刻画资产的时空相关性,并利用混合专家(Mixture of Experts)结构在不同市场状态下动态切换交易逻辑,从而避免单一策略在多变市场中的过度泛化。这表明强化学习不仅可以用于学习权重分配规则,还可以作为统一框架,融合市场风险识别、策略切换与资金管理等多个决策层面,在长期收益与风险控制上取得更稳定的表现。
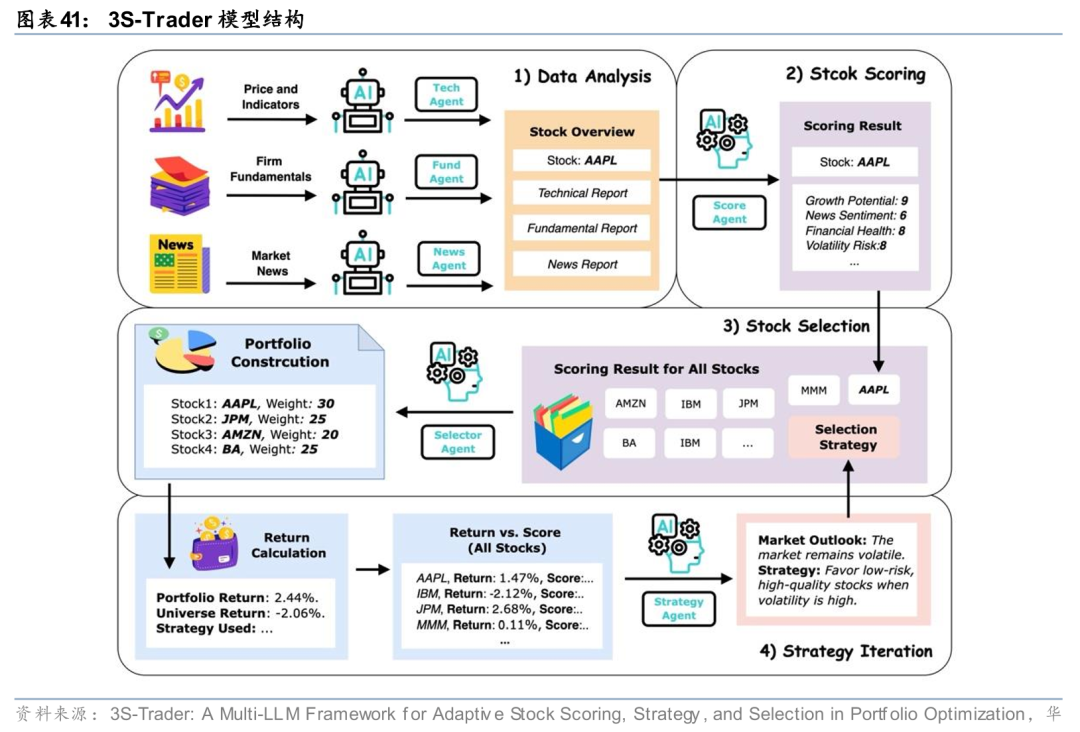
除了强化学习,近年来大型语言模型(LLM)在投资组合优化中也展现出独特优势。相比传统方法,它们能够直接处理多模态金融数据,整合价格走势、财务指标和市场资讯,实现跨资产的全面分析,从而在组合构建中更好地解决信息异质性、跨期依赖以及多维风险权衡等问题。Chen等人(2025)提出的3S-Trader模型,通过多个 LLM 代理分别分析新闻、财报和技术指标,对每只股票生成多维评分,再结合策略迭代模块进行组合构建与调整。3S-Trader 的设计展示了 LLM 在投资组合端到端建模中的潜力:不仅能够整合多源信息,还能提供可解释的策略优化方向。尽管该模型暂未直接对LLM基座开展训练微调,但这一多智能体协作的框架思路,为后续训练LLM基座,直接输出投资组合权重并平衡风险与收益,提供了一定的思路指引。
参考文献
Wei, Z., Chen, D., Zhang, Y., Wen, D., Nie, X., & Xie, L. (2025). Deep reinforcement learning portfolio model based on mixture of experts. Applied Intelligence, 55(5), 347.
Chen, K., Ahmad, H., Goel, D., & Szabo, C. (2025). 3S-Trader: A Multi-LLM Framework for Adaptive Stock Scoring, Strategy, and Selection in Portfolio Optimization. arXiv preprint arXiv:2510.17393.
AI+宏观量化的新世界
宏观量化是量化领域的一个小众分支,主要采用自上而下的视角,系统地捕捉宏观层面的β收益机会。其核心方法论在于,运用量化工具将繁杂的宏观信息转化为可观测、可跟踪的结构化因子,从而系统性地分析宏观经济如何影响资产价格,并据此进行前瞻推演。与许多由数据直接驱动的量化策略不同,宏观量化更重逻辑和模型的可解释性,数据服务于逻辑,而非替代逻辑判断。本节将回顾团队在宏观量化领域的主要研究成果,并结合AI技术的最新发展对未来的研究路径进行展望。
宏观量化的过去和现在
自2016年发布首篇报告《市场的轮回-金融市场周期与经济周期关系初探》(2016-02-21)以来,我们在宏观量化研究上深耕易耨,研究体系不断迭代:从早期对经济周期的验证、建模与实践,逐步拓展至对宏观经济状态更全面、更高频的刻画与应用,以应对宏观交易复杂化、叙事冲击常态化的市场环境。与之同步,我们的宏观因子体系也经历了1.0版本至2.0版本的迭代。1.0体系侧重于刻画宏观现实,聚焦于中长期经济周期建模;而2.0体系则更注重融合高频现实与市场预期,因为随着宏观现实周期波动幅度的收窄,市场交易重心部分转向高频数据与预期差博弈。
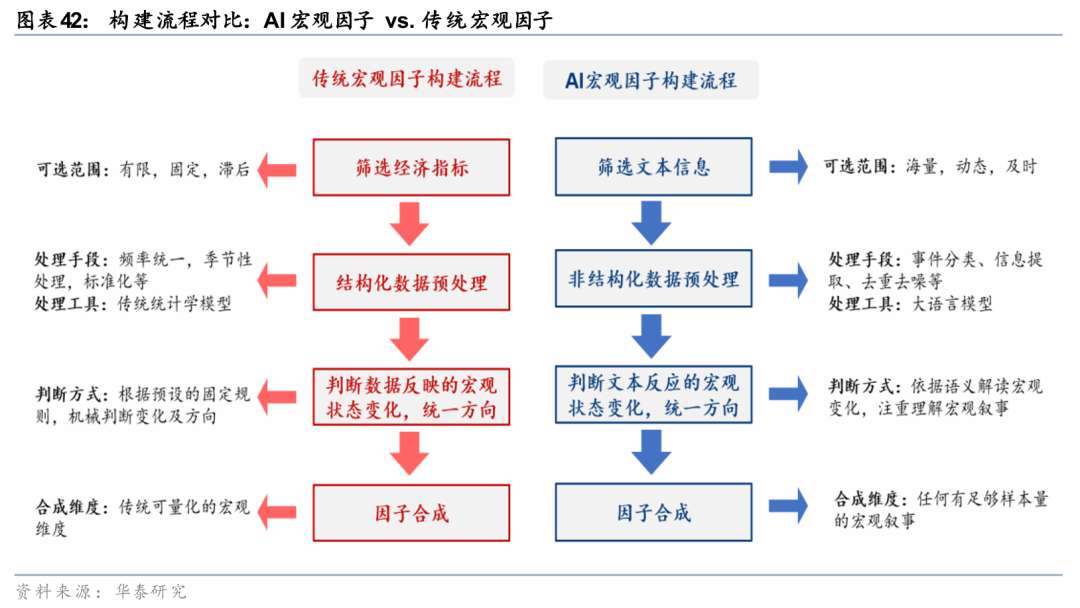
我们对于宏观量化的定位是“逻辑驱动,数据验证”,因此早期研究更多侧重于运用定量方法验证宏观逻辑,为既定的定性判断提供可靠的数据支持。在这一阶段,我们倾向于采用结构清晰、解释性强的量化方法,而非复杂的“黑箱”AI模型。例如,通过傅里叶变换、小波分析、HP滤波等技术分解经济指标的周期特征;利用Nowcasting模型对滞后公布的宏观数据进行实时预测;或是借助因子模拟(Factor mimicking)方法,从资产价格中提取市场隐含的宏观预期。这些方法本质上是辅助分析的工具,服务于既有的宏观推理框架。
随着可解释人工智能与大语言模型技术的突破,宏观量化在非结构化数据利用、经济叙事建模及非线性关系刻画上展现出全新可能。《人工智能96:LLM赋能资产配置:基于新闻数据的AI宏观因子构建与应用》(2025-09-24)中,我们通过LLM深挖新闻数据构建的AI宏观因子,不仅能更敏锐地捕捉宏观现实与预期的边际变化,对资产价格也展现出更强的解释力,这为因子构建提供了新的可行路径。但技术的发展同时伴随着技术门槛的降低,或会加快同质化策略的衰减速度,尤其对于宏观量化这个小样本领域。我们认为“私域数据”的差异化获取能力和“复杂叙事”的建模能力或是未来宏观量化策略的胜负手。
宏观量化的未来
从解读数据到理解叙事
相比于传统的经济数据建模,对市场叙事与预期的细致化建模是一个更具探索性的方向。因为叙事不仅能反映和传播基本面信息,更能在特定阶段主导短期市场的定价逻辑,而传统数据在此时可能呈现为一种“滞后结果”。在大模型技术的助力下,我们能够直接从文本这类信息含量和逻辑密度更高的非结构化数据中,提炼并解构深层逻辑链条,从而利用宏观叙事,更灵敏地捕捉宏观状态的切换信号。此外,“叙事建模”的逻辑下,策略可以不再僵化地执行静态规则,而是通过理解叙事的动态演进实现自适应的调整。
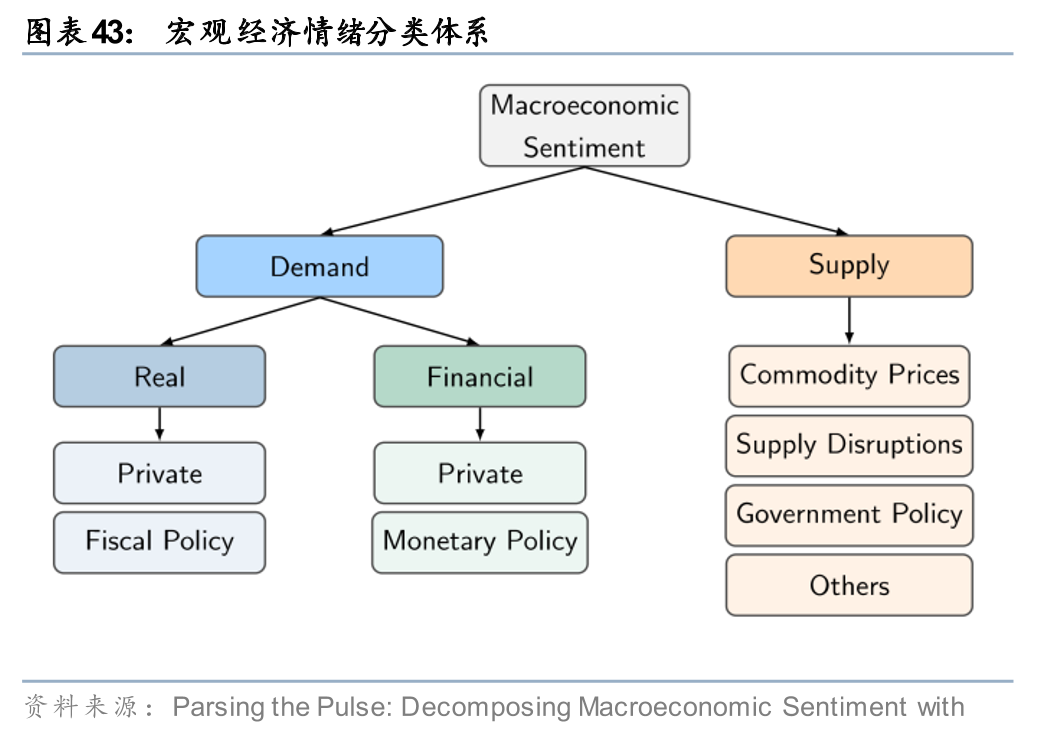
学界和业界对“叙事建模”的尝试已从关键词匹配、主题模型等简单文本分析方法转向了基于LLM的深度逻辑挖掘,并用于宏观监测和资产定价等领域。宏观监测方面,国际清算银行(BIS,2025)运用LLM对财经新闻进行多层级分类与打分,构建出基于底层驱动因素的子指数,并汇总为需求、供给及总体情绪指数。该情绪指数与实际经济指标相关性高,且具备领先性,可作为高频实时监测工具。例如,通胀情绪指数能紧密跟踪CPI、PCE等实际通胀变化,对核心通胀率的预测表现突出,并在疫情后通胀大幅上涨前已发出早期预警。
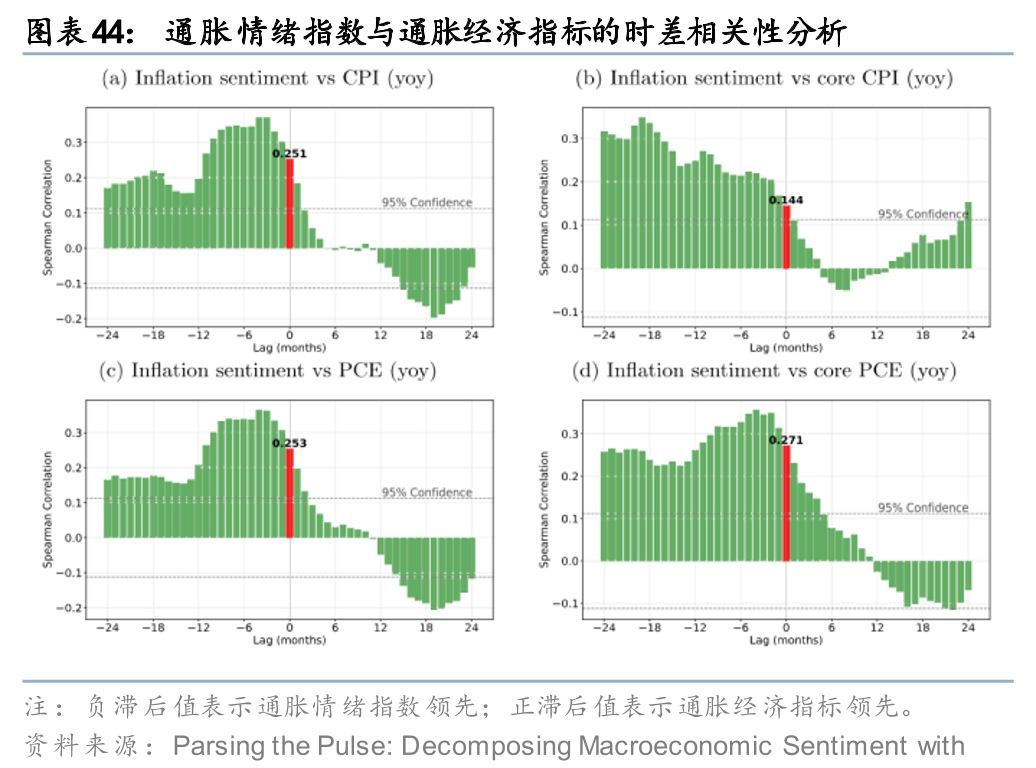
使用LLM构建文本指数时,对文本信息的情感赋分效果是关键。桥水AIA实验室(2025)研究发现LLM在预测时存在过度保守的“对冲”倾向,即将预测概率向0.5靠拢,即使面对高确定性事件也倾向于给出中庸概率,导致预测的锐度不足。对此,桥水AIA实验室(2025)提出应用Platt缩放等统计校正技术对LLM的对冲倾向进行极端化处理,输出最终概率,发现这种校准方法比复杂的提示工程更为鲁棒和有效。
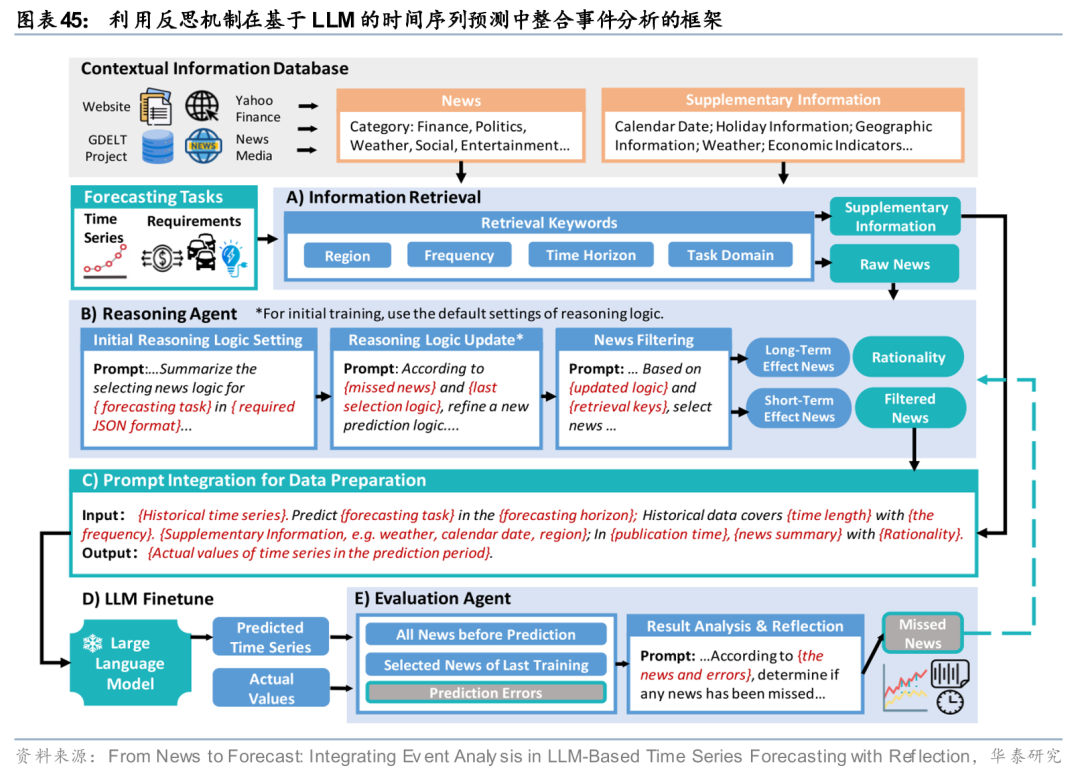
资产定价方面,Wang等(2024)提出了一种基于反思机制的新闻增强型时间序列预测框架。该框架的特点在于:(1)保留完整语义:直接将原始新闻文本(而非人工构造因子)通过提示工程转化为带有时序与因果的语言描述,作为模型输入,从而避免结构化导致的信息损失;(2)设置反思机制:引入评估代理,在验证集上比较预测误差与实际值,识别被遗漏的关键新闻,并据此更新新闻选择逻辑,进行自适应调整。Wang等(2024)的研究结果表明,多轮反思迭代的机制可以降低模型的训练误差;模型在电力、汇率、比特币等领域的测试中均优于主流基线模型(如Informer、Autoformer、TimesNet等),尤其在受突发事件影响明显的电力需求预测中表现突出。
从线性关系刻画到复杂系统仿真
传统宏观量化研究的痛点在于,受限于样本量和结构化数据建模的局限性,往往依赖线性模型刻画宏观与资产关系,虽易于解释却牺牲了真实世界的复杂性。如今,大模型等AI技术突破了数据规模与建模能力的双重限制:既能处理海量非结构化文本,拓宽信息边界、提高样本频率;也能借助“硅基智能体”仿真框架,刻画多主体间的非线性互动与动态反馈。
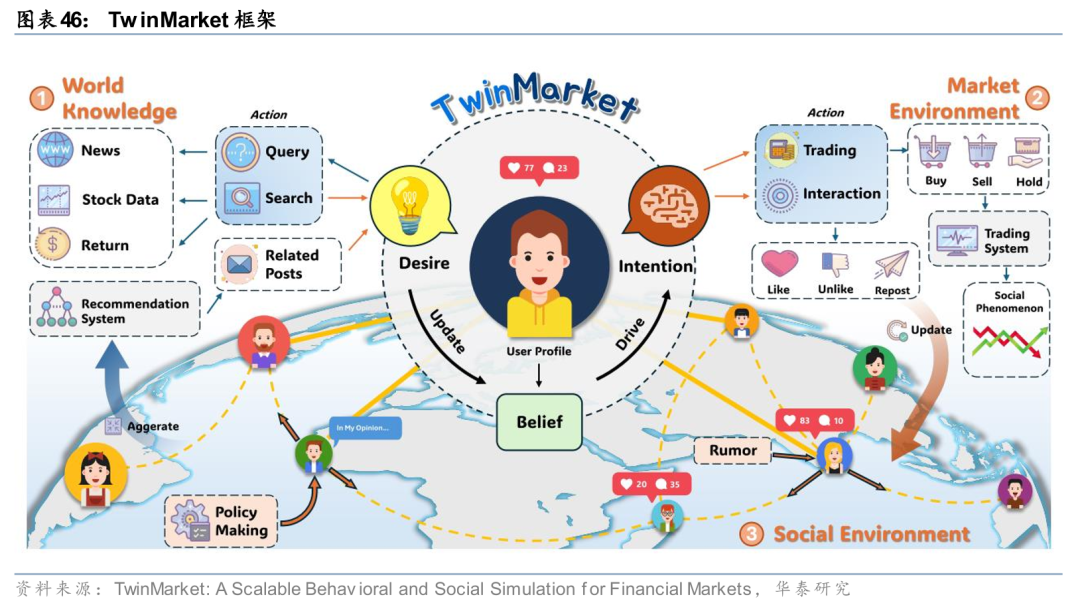
基于主体/智能体的建模(Agent-Based Modeling,ABM)通过模拟大量异质性个体(如消费者、银行、企业等)在特定规则下的交互,来观察宏观系统如何产生复杂的现象。TwinMarket(Yang等,2025)是一个通过融合信念-欲望-意图认知架构与动态社交网络交互,模拟金融市场中个体行为如何涌现出宏观复杂结构的多智能体框架。该框架能够复现多种金融“风格化事实”,例如资产收益的肥尾分布、波动率聚集、杠杆效应以及成交量与收益率的关系,实现对宏观市场结构与资产价格动态的可解释、可扩展建模。
参考文献
AIA Research Lab. AIA Forecaster: Technical Report[J]. arXiv preprint arXiv:2511.07678, 2025.
Kwon, Byeungchun, Taejin Park, Phurichai Rungcharoenkitkul, and Frank Smets. *Utilizing Large Language Models to Parse the Pulse: Decomposing Macro Sentiment* [J]. BIS Working Papers, 2025.
Wang, Xinlei; Feng, Maike; Qiu, Jing; Gu, Jinjin; Zhao, Junhua. From News to Forecast: Integrating Event Analysis into Time Series Prediction with Reflective Reasoning in Large Language Models[J]. arXiv preprint arXiv:2409.17515, 2024.
Yang, Y., Zhang, Y., Wu, M., Zhang, K., Zhang, Y., Yu, H., Hu, Y., & Wang, B. (2025). TwinMarket: A Scalable Behavioral and Social Simulation for Financial Markets. arXiv preprint arXiv:2502.01506v5.
AI策略跟踪
AI全频段量价模型
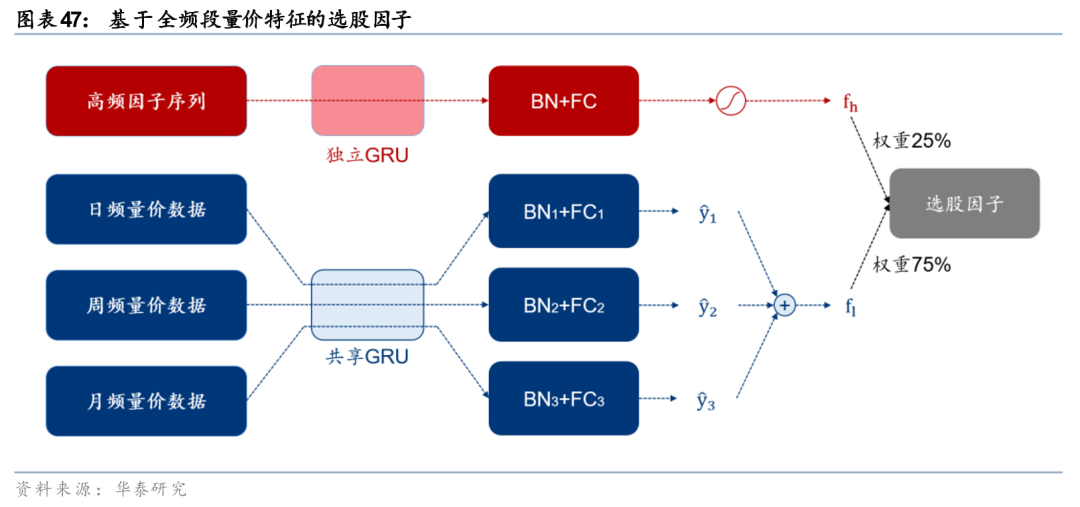
华泰金工研报《基于全频段量价特征的选股模型》(2023.12.8)中,使用市场中各种频率的量价信息,包括日k线、周k线、月k线等低频量价数据,以及分钟线、逐笔成交、逐笔委托等高频量价数据。将多频率数据进行一定的预处理,再输入AI模型进行训练,最终输出选股信号“全频段融合因子”。该因子预测的是个股未来10个交易日相对市场的超额收益。
基于全频段融合因子构建中证1000增强组合,组合构建方式如下:
1、 成分股权重不低于80%;
2、 个股权重偏离上限为0.8%;
3、 barra因子暴露小于0.3倍标准差;
4、 周频调仓,周双边换手率不超过30%;
5、 交易费用为双边千分之四。
自2017年初回测以来,该组合每年都稳定跑赢基准指数中证1000,年化超额收益率为21.86%,年化跟踪误差为6.05%,信息比率为3.62,超额收益最大回撤为7.55%,超额收益Calmar比率为2.89。在2024年初至今的样本外,超额仍能延续,其中2024年超额收益5.06%,2025年超额收益24.68%。
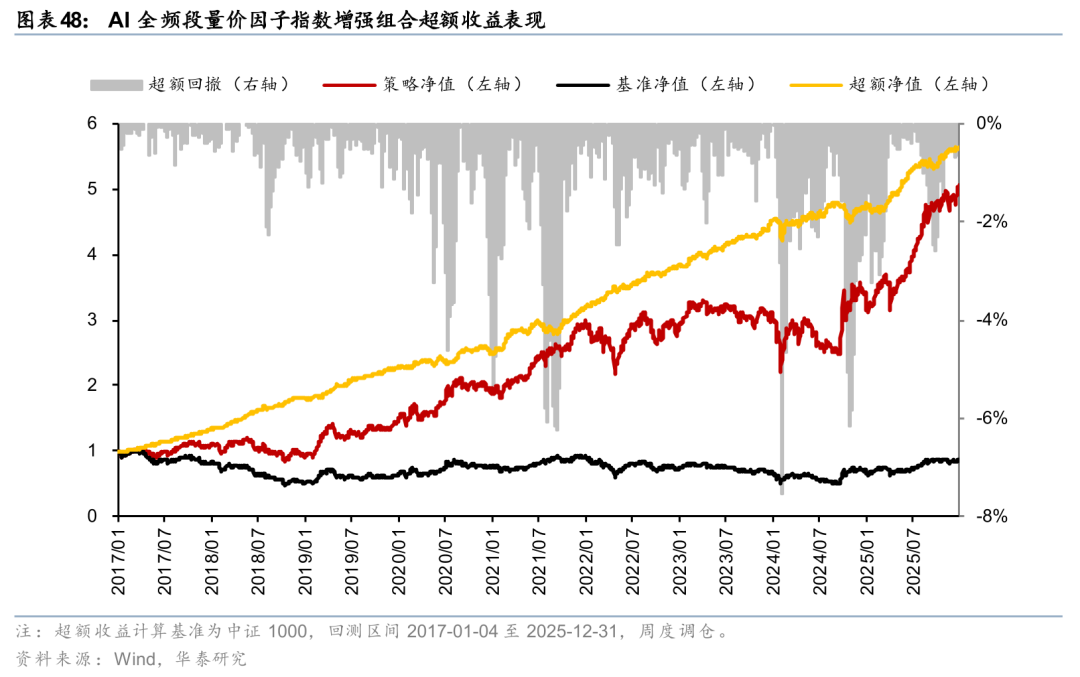


Master因子
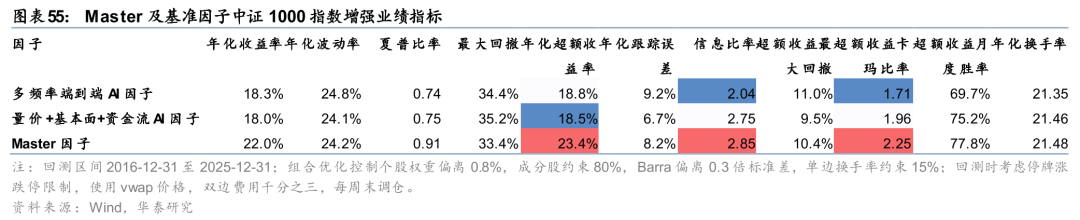
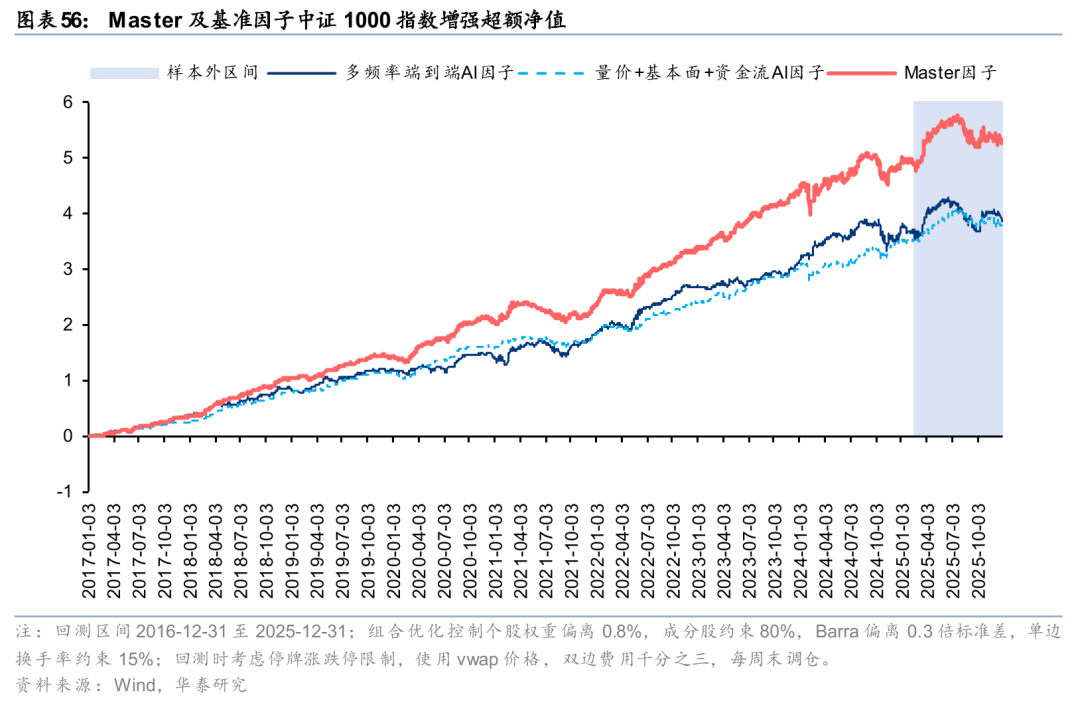
华泰金工前期研究《人工智能86:与时偕行:AI模型如何应对数据漂移》(20250221)基于GRU和三层注意力的Master模型,通过线性门控/注意力门控模块引入市场特征变量得到Master因子,因子在样本外的表现持续较优。
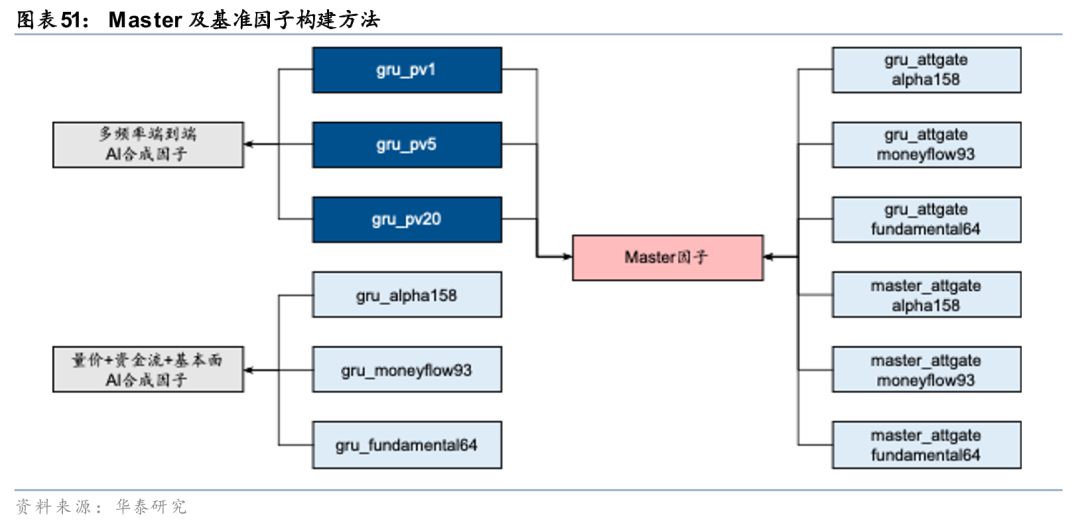

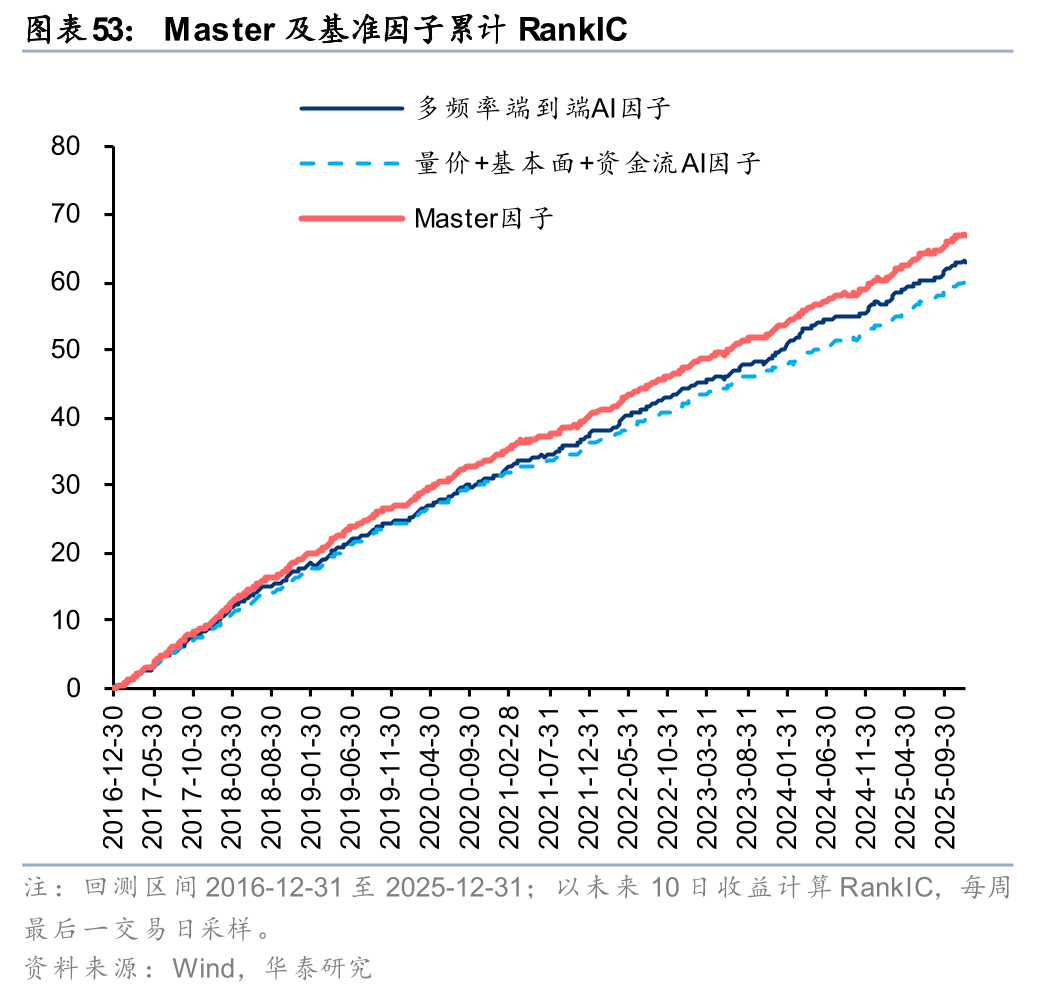
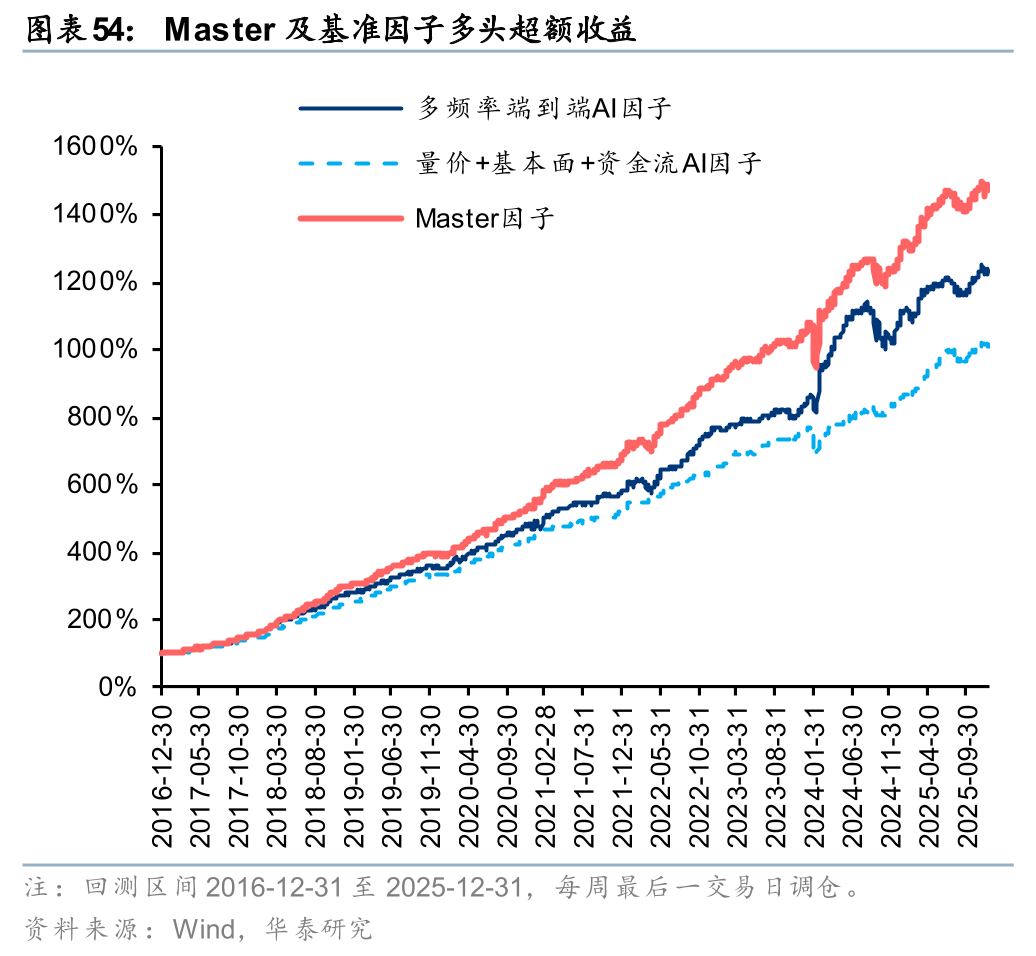
基于Master因子构建中证1000指数增强组合,样本外表现可圈可点。自报告发布后至2025年7月底超额趋势较强,累计获超16%超额,但其后AI因子普遍回撤的背景下组合超额收益也有所下滑,截至2025年底累计获取8.4%超额收益,与多频率端到端AI因子7.0%超额收益、量价+基本面+资金流AI因子7.7%超额收益相比仍稳定占优。
大模型舆情选股因子
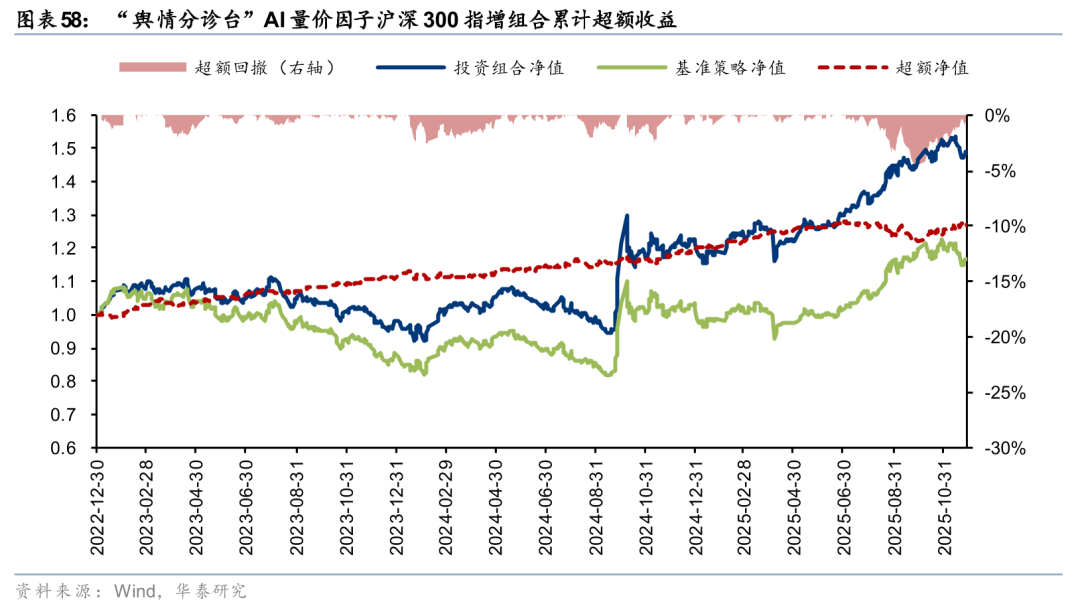
“舆情分诊台”因子将大语言模型(LLM)对新闻舆情的情感分析能力引入AI量价模型,基于市场情绪动态选择AI量价专家路由,“情绪分域、量价建模”,有效融合了另类舆情信息与量价数据,提升指数增强组合表现。详见报告《LLMRouter-GRU:“舆情分诊台”赋能AI量价因子》(2025-07-17)。

舆情分诊台因子在25Q3同样经历了一定超额回撤,目前跌幅已基本修复。未来,对“乐观域”加强动量效应学习,或有望改善“机构抱团”行情期间的策略回撤情况。
PortfolioNet2.0因子
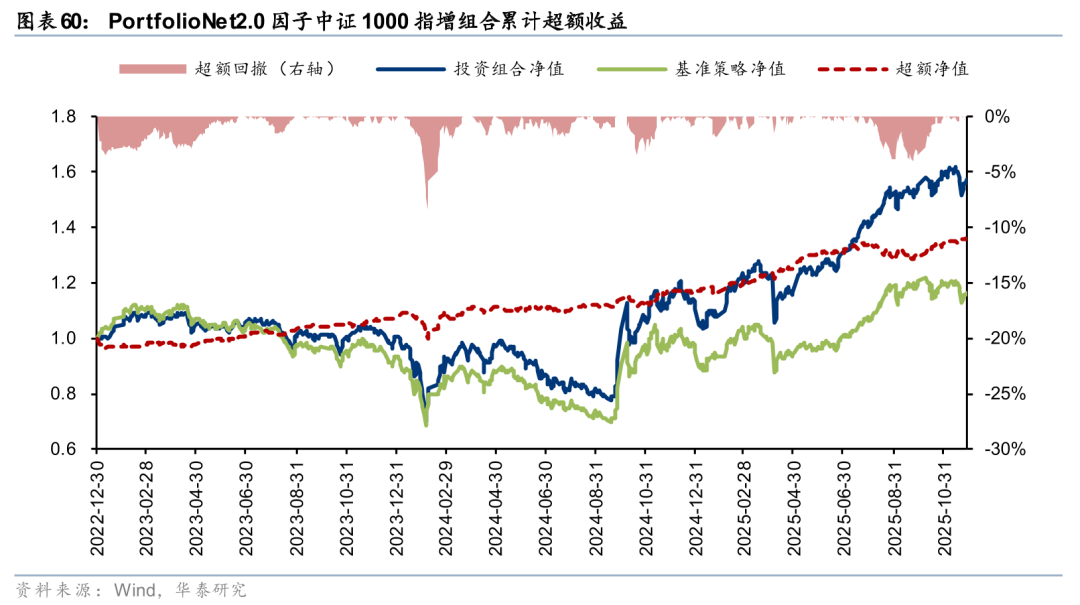
PortfolioNet2.0选股因子通过将风格模型引入网络,对组合约束项赋予可微性能,让AI量价因子追求较高收益弹性,捕捉 Pure Alpha 之外的风格收益。详见报告《PortfolioNet 2.0:如何兼取风格收益与Pure Alpha》(20251216)。

从样本内回测结果看,PortfolioNet2.0因子在25Q1的科技股行情中表现较优,对成长风格予以超配,一定程度上避免了AI量价策略偏好红利导致的潜在回撤风险。因子发布于2025年12月,后续将对策略表现保持跟踪。
LLM-FADT文本策略
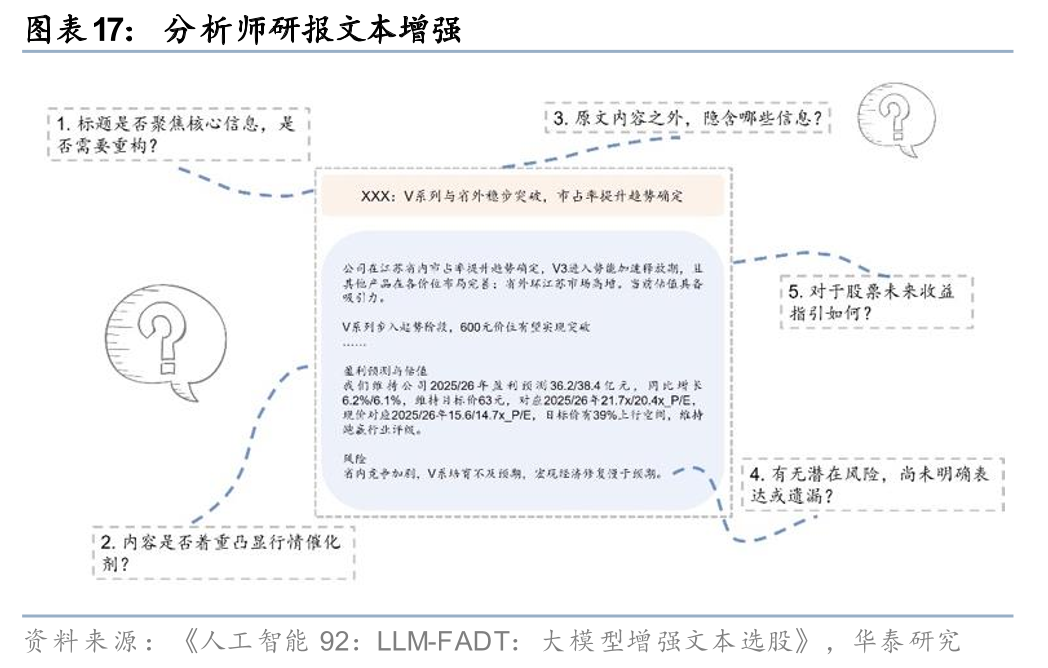
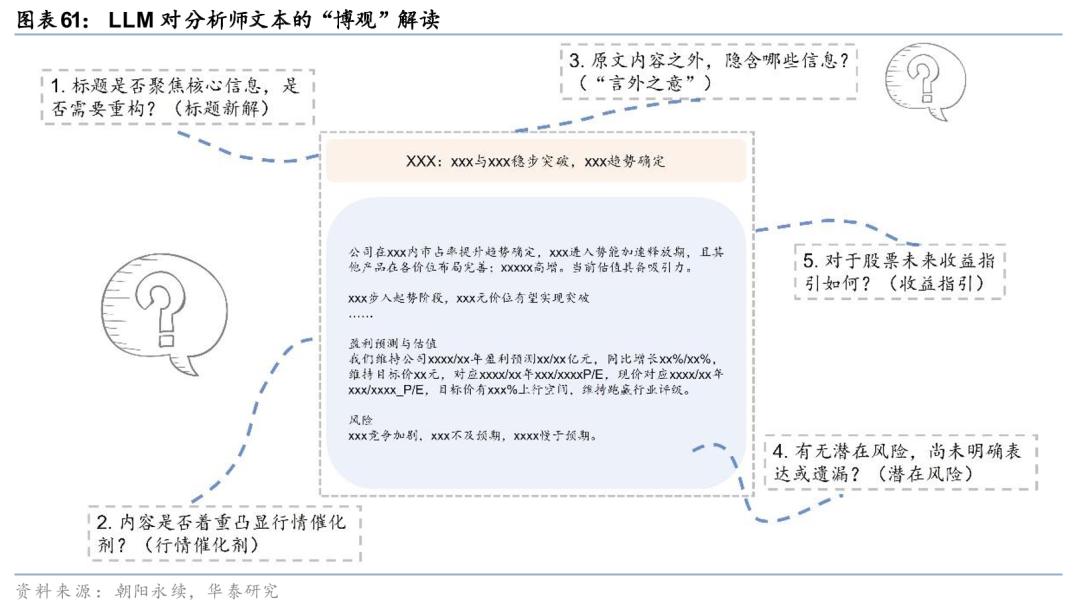
在前期研究《人工智能92:LLM-FADT:大模型增强文本选股》(20250610)中,我们考虑到原始分析师研报虽然通常以精确有效的信息传达为核心目标,然而受限于篇幅、语言组织等方面,对于读者而言,研报中或多或少蕴含着需要额外梳理的信息。我们对研报标题及摘要提出多个问题,例如“标题是否聚焦核心信息,是否需要重构”,“内容是否着重凸显行情催化剂”,“原文内容之外隐含哪些信息”,“有无潜在风险尚无明确表达或遗漏”,“对于股票未来收益指引如何”,要求大模型逐一发表见解,以充分体现大模型对文本的“博观”解读。
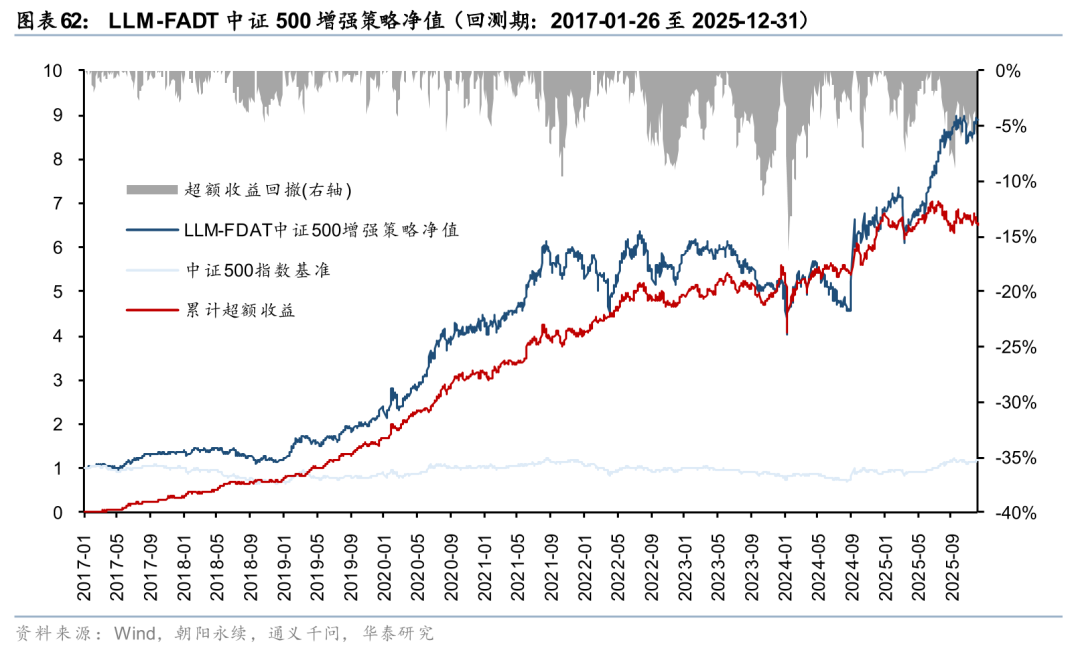
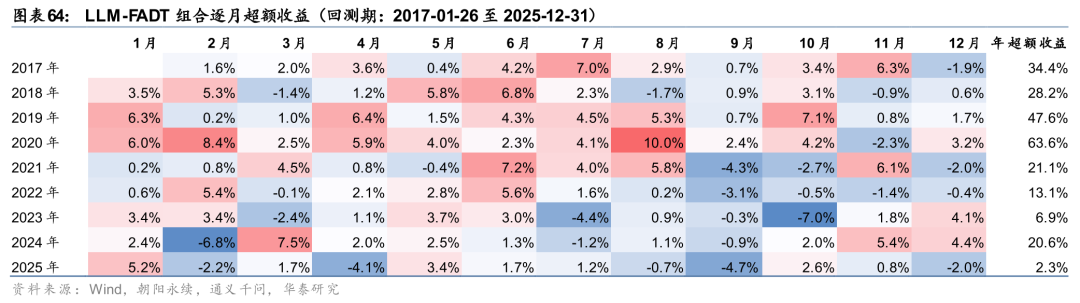
截至2025年12月31日,文本LLM-FADT组合本月以来相对中证500超额收益-2.0%,今年以来超额收益2.3%,本周超额收益回撤。自2017年初回测以来年化收益率28.93%,相对中证500超额年化收益26.43%,组合夏普比率1.13,信息比率2.08。

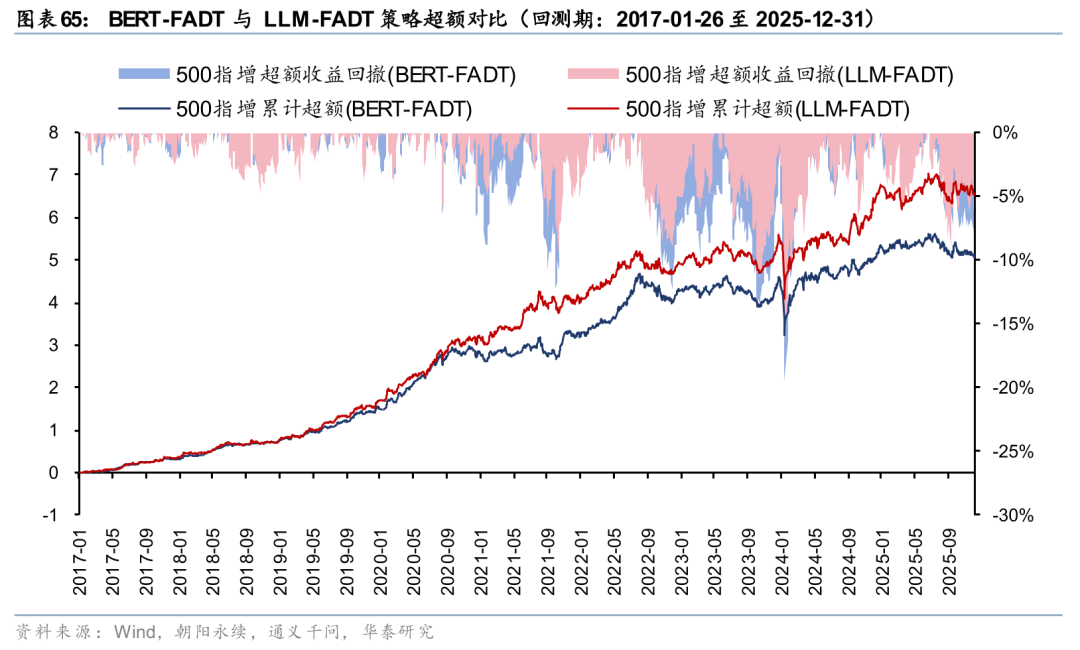
相比于仅依赖原始文本的BERT-FADT,LLM-FADT策略总体更为稳定,超额回撤相对较小。自2024年10月以来,LLM-FADT策略超额总体稳定跑赢BERT-FADT,LLM-FADT策略超额回撤优于BERT-FADT。
风险提示
通过人工智能模型构建选股策略是历史经验的总结,若市场规律改变,存在失效的可能;人工智能模型可解释程度较低,归因较困难,使用须谨慎;大模型是海量数据训练获得的产物,输出准确性可能存在风险。
研报:《AI量化的当下与未来》2026年1月22日
何康 分析师 S0570520080004 | BRB318
沈洋 分析师 S0570525070013
徐特 分析师 S0570523050005
卢炯 分析师 S0570525070012
浦彦恒 联系人 S0570124070069
孙浩然 联系人 S0570124070018
李薇 联系人 S0570124070087
>>>查看更多:股市要闻
