AI 链:看好 Scaling Law 仍然有效持续带动算力链发展
AI 模型:Scaling Law 继续有效,中美路径分化
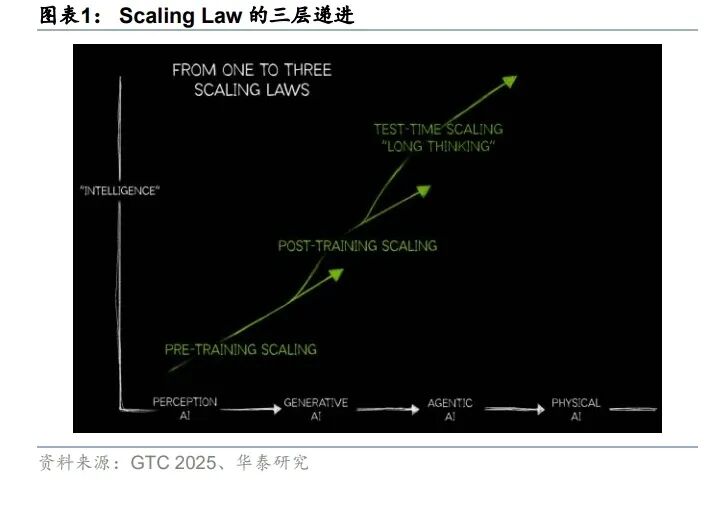
Scaling Law 迭代,模型性能继续提升
从维度上看,Scaling 从预训练拓展到后训练和推理,为模型能力增强带来新的路径。早 期的 Scaling Law 主要聚焦于预训练阶段,强调增加模型大小、数据集大小和训练量,就可 以提升大语言模型的性能。2024 年 9 月 OpenAI 发布 o 系列模型以来,强化学习被系统性 引入后训练流程,使模型在强化学习中形成可扩展的能力增益。此后,大模型通过增长思 维链,通过增加思考时间提升模型效果。Scaling Law 的拓展为模型的性能带来新的提升 路径,包含三种 Scaling Law 的推理模型在性能对比中占据优势。
从算法上看,各家大厂通过算法优化提升模型性能,推动 Scaling Law 继续有效。部分算 法的改进路线在于 Scaling Law 本身,阿里的千问团队在 Scaling Law 的基础上拓展了数据 并行维度,在不显著增加显存和推理时间的情况下增加计算量,提升效果。Meta 团队推出 2-单纯形注意力,在标准 Transformer 的基础上,增加了新的键矩阵和值矩阵,将二维关系 拓展到三维关系,对 Scaling Law 的指数项进行优化;部分算法的改进路线为 LLM 组件的 优化,例如 Kimi 使用 Muon 替代一般的 AdamW 优化器,提升优化速率;部分算法尝试解 决 LLM 的遗忘问题,例如 Google 参考大脑记忆过程提出嵌套学习方案,将模型结构设计 和模型参数训练用嵌套学习的语言统一化,尝试缓解 LLM 的顺行性遗忘,而 DeepSeek 则 用视觉方案的模糊去平滑 LLM 的遗忘过程,提出 DeepSeek-OCR 模型。算法的改进也是 Scaling Law 继续有效的重要原因。
Scaling Law 要求数据和参数量同比例增长,头部厂商通过新增标注和合成数据等方法持 续扩容训练数据。2022 年 3 月,DeepMind 提出 Chinchilla Scaling Laws,指出为了使模 型达到最佳性能,模型参数量应与训练集的大小成等比例扩张,并给出算力、模型和训练 Token 间的比例关系。我们观察到新近模型的训练 tokens 继续上行:例如阿里 Qwen 系列 由 18 万亿提升至 36 万亿,Meta 在训练 Llama 4 Scout 时引入部分社交数据,使总体训练 数据约达 40 万亿。我们认为,随“垂类”数据与新标注数据的不断累积,训练 tokens 仍 将增加,且从模型泛化性和性能表现来看,OpenAI、Google 等头部模型的训练规模或高于 公开口径。
Gemini 3 性能领先,背后是预训练和后训练的持续改进,预训练继续有效。2025 年 11 月 19 日,Google Gemini 3 发布,在各类测试中达到性能领先,高于其他可比模型。Google DeepMind 研究副总裁兼深度学习负责人 Oriol Vinyals 表示,Gemini 3 背后的秘密是改进 预训练和后训练阶段,他们认为预训练的 Scaling 尚未结束,Gemini 3 和 Gemini 2.5 之间 的差距较大,而后训练阶段仍然是全新领域,算法方面仍有很大的进步和改进空间。我们 认为,Scaling Law 的几个阶段仍有较大的提升空间,看好 Scaling 继续推动模型性能提升 和算力需求增长。
模型迭代:中美的差异化路径
海外:增大算力推动模型性能提升。Grok 模型系列模型迭代,主要通过将大量算力投入不 同的 Scaling Law 维度,Grok 2 到 Grok 3 的迭代,主要通过将预训练算力扩大约 10 倍带 来性能跃升;Grok 3 的推理模型标志着 Grok 模型进入后训练阶段;至 Grok4 发布,其后 训练(Reasoning)相较 Grok3 再度将算力放大约 10 倍,使得后训练算力需求接近预训练。 从算力建设端来看,据 xAI 官网,Grok 4 依托 20 万卡级别的 Colossus 大规模集群进行训 练,OpenAI 在后训练 Scaling 领域或也进入重投入阶段, 从“Stargate(星际之门)”项目 的规划细节与算力布局来看,其在后训练方向的资源投入已具备显著规模。

国内:聚焦架构优化和成本降低。在受限于算力基础层的情况下,国内基础模型的发展更 依赖于架构优化和效率提升。阿里为进一步增强模型在长上下文与大规模参数条件下的训 练及推理效率,其 Qwen3-Next 在保持 Transformer 与 MoE 总体框架不变的前提下引入线 性注意力和传统注意力的混合机制,DeepSeek V3.2 引入动态稀疏注意力,实现厂商下文 推理的高效稀疏化,分阶段计算注意力,从而显著提升模型训练和推理效率。Kimi 使用 Muon 优化器,在 3B/16B 的 MoE 模型上,用一半算力达到相同结果。根据 CNBC 报道,Kimi K2 Thinking 的训练成本为 460 万美元,对比之下 DeepSeek V3 560 万美元,OpenAI 则花 费了数十亿美元。总体上来看,国内通过架构的精细优化设计,实现成本的降低。
互联:算力互联推动互联组件需求加速增长
AI 算力需求的扩张催生了三大互联需求。1)伴随单一集群的不断扩大,从此前的千卡集群, 到如今的万卡,再到将来的几十万卡甚至百万卡集群,Scale-out 层级的互联不断扩大。2) 伴随 AI 推理需求的放量,张量并行、专家并行等并行策略对卡间通信与内存提出了更高的 要求,Scale up 网络可以实现高带宽低延迟的数据传输与内存池化,成为推理放量后的必 然选择。3)由于单个数据中心电力/散热等条件存在限制,Scale across 互联可以使得多个 数据中心跨越几十公里连接成一个统一的集群,打破单一数据中心在电力、功率与物理中 心的限制。
Scale-out 域的扩大带来互联组件非线性增长
Scale-out 域一般采用叶脊架构,互联组件需求随 GPU 增长而增加。Scale-out 域是每个 GPU 通过网卡与交换机相连,从而与其他 GPU 进行互联的域。Scale-out 域通过交换机将 GPU 两两相连,从而实现十万甚至百万卡集群的构建,相对的,对于互联的速度要求低于 Scale-up,一般应用于流水线并行、数据并行等场景。由于 Scale out 域涉及柜外的互联, 需要使用光模块进行光-电转化,因此集群内 GPU 数量增长的背景下,交换机、光模块的 需求也随之增加。
互联组件随着 GPU 增长非线性增长。我们注意到,随着 GPU 数量的增长,构建 Scale-out 需要的交换机、光模块数量并非线性增长,斜率存在逐步增长的趋势。
互联组件的非线性增长主要因为 Scale-out 网络层数的增加, 我们看好算力需求增长对互 联组件的强劲推动。根据我们的测算,在使用 64 口 400G 交换机(Nvidia Quantum-2 QM9700)的情况下,当 GPU 数量小于 2048 时,只需要两层交换机即可实现 Scale-out 网 络的构建,但 GPU 数继续增长后,需要三层网络才能完成 GPU 间互联。网络结构的复杂 化使得互联组件的需求非线性增长,两层网络的交换机数量是 GPU 数的 4.7%,光模块是 GPU 数的 2.5 倍,但拓展到三层后,交换机和光模块比例分别达到 7.8%和 3.5 倍。
Scale-up 域的拓展带来互联组件的额外需求
Scale Up 侧交换机规模快速增长,目前市场规模已超过 Scale Out 以太网和 InfiniBand 市场总和,2028 年市场规模有望达 130 亿美元。随着模型并行计算带来的带宽需求持续攀 升,AI Scale up 机柜方案逐渐被市场验证(英伟达 NVL72、华为 384 等),Scale UP 网络 互联市场需求快速增长。根据 Lightcounting 数据,目前 Scale Up 市场规模已超过 Scale Out 以太网和 InfiniBand 市场总和,2028 年有望达到 130 亿美元,其中包括以英伟达 Feynman 架构(2028)为代表的七代 NVLink 技术,以及新的 SUE、Ultra Accelerator Link(UALink) 规范,将提供一条从专有协议向 200G/通道标准化的路径。同时据 Lightcounting 预测,到 2028 年,UALink 交换机可能占据 Scale up 交换机市场总量的 20%。
Scale-up 域从柜内拓展到柜外,带来对互联组件的新增需求。Scale-up 域的核心是多 GPU 共享内存,过去以机柜内的铜缆互联为主,随着对高速互联的需求不断增长,Scale-up 域 逐渐从柜内拓展到柜外,类“超节点”模式的 Scale-up 域引发越来越多的关注。以 Google 为例,Google 的 TPU V7 集群的 Super Pod 包含 9,216 个共享内存的 TPU 卡,柜内的 64 个芯片通过 PCB 或铜缆连接,柜间 144 个机柜中的 TPU 通过光路交换机连接,带来对光 路交换机和光模块的增量需求。
重视 Scale-up 域的拓展趋势,看好 Scale 域拓展对互联组件的推动。我们对 Google SuperPod 的交换机和光模块需求进行测算,在假设使用 300*300 光路交换机的情况下,结 合 TPU 间 3D 堆叠的连接结构,我们得到 9,214 卡的 SuperPod 使用约 48 个光路交换机和 13,824 个光模块,对应新增 1.5 倍的光模块需求。今年以来超节点形式的产品在国内外持 续推出,我们也看到 TPU 性能得到广泛认可,看好后续互联组件需求的持续增长。
单一数据中心限制驱动 Scale across(DCI)扩展迅速
Scale Across(DCI、数据中心互联)市场规模增长迅速,跨 DC 训练与推理将具备可行 性。Scale Across 通过高速光网络连接分散的数据中心形成一个统一的计算集群,打破单 一数据中心电力、散热与物理空间的限制,实现算力资源的跨区域协同,是 Scale up/Scale out 外更广的互联。英伟达也在今年 8 月份推出 Spectrum-XGS 交换机,通过优化以太网算 法,实现跨几十公里、甚至跨城市的稳定互联,把多个数据中心“拼接”成一个统一的超 级计算单元,一个巨大的“AI 工厂”。根据 Marvell 预测,DCI 市场规模有望从 2023 年的 10 亿美元增长至 2028 年的 30 亿美元,23-28E CAGR 达到 25%。
AI 芯片:单芯片及系统级性能提升并驱,关注产能瓶颈改善
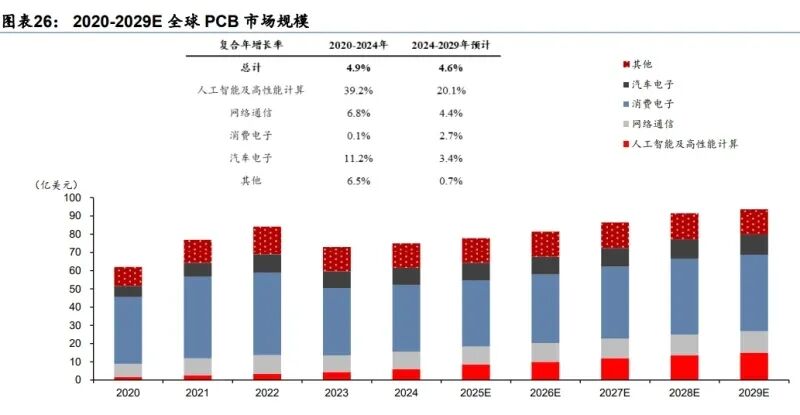
AI 军备竞赛仍在持续,预计 2026 年全球主要 CSP 厂商资本支出同比增长 40%。全球科技 巨头持续投入 AI 军备竞赛,不断加码数据中心资本支出,TrendForce(11 月)上修 2025 年谷歌、亚马逊、Meta 等全球八大 CSP 厂商资本支出合计总额增速至 65%,并预计 2026 年各大 CSP 厂商将维持积极投资节奏,合计资本支出将达 6000 亿美金,同比增速为 40%。
AI 芯片需求保持旺盛,2030 年全球 GPU 市场规模预计 4724 亿美元,25-30E CAGR 达 35.19%。大模型训练和推理对 AI 芯片需求保持强劲,11 月 8 日,黄仁勋受访时表示,公 司业务表现非常强劲,并为月复一月增强。根据 Verified Market Research 的数据,2024 年全球 GPU 市场规模为 773.9 亿美元,2030 年有望达到 4724 亿美元,对应年复合增长率 高达 35.19%,呈现强劲增长态势。其中,中国智算中心建设亦持续加速,IDC 数据显示, 中国智能算力规模预计将由 2020 年的 75.0EFLOPS 增至 2028 年的 2,781.9EFLOPS, CAGR 达 57.1%。
AI 芯片国产替代仍为大势所趋。根据 Bernstein Research 数据,2024 年中国 AI 加速芯片 市场中,英伟达和 AMD 合计占据 71%的市场份额,其中英伟达以 66%的份额占据绝对主 导地位。在此背景下,受益于国产替代趋势及供应链安全需求,国内计算芯片公司正迅速 发展。当前,美国政府仍严格限制高性能 AI 芯片对华出口,国内市场 AI 芯片国产替代意愿 较高,伴随国产 AI 芯片厂商技术实力快速提升,综合考虑性价比优势以及安全性,我们认 为即便后续美国政府对华出口高性能 AI 芯片限制有所放松,国产替代仍为大势所趋。
国产 AI 芯片单芯片及系统级性能提升并驱,2026 年产能瓶颈有望进一步改善。国产 AI 芯 片设计水平提升迅速,目前主流产品性能表现已向英伟达 A100 看齐。例如,根据沐曦招股 说明书,其当前主要产品 C500/C550 系列算力表现处于英伟达 A100 区间,而下一代产品 曦云 C588 芯片将大幅缩小与英伟达 H100 产品差距。除了提升单芯片性能表现之外,国内 AI 芯片厂商研发逻辑亦逐步向系统级性能提升过渡。2025 年华为开发者大会上,华为宣布 基于 CloudMatrix 384 超节点的新一代昇腾 AI 云服务全面上线,CloudMatrix 384 超节点将 384 颗昇腾 NPU 和 192 颗鲲鹏 CPU 通过全新高速网络 MatrixLink 全对等互联,形成一台 超级“AI 服务器”,单卡推理吞吐量跃升到 2300 Tokens/s,与非超节点相比提升近 4 倍。 此外,当前国内 AI 芯片放量瓶颈在先进制造产能,伴随国内代工厂先进制造能力持续提升, 2026 年国产 AI 芯片产能瓶颈有望取得较大改善,相关公司包括寒武纪、海光信息等。
互联网厂商 AI 芯片采购“第三方+自研”路径并行,带动定制芯片市场空间快速增长。国 内互联网厂商除积极采购国产 AI 芯片外,亦纷纷布局自研 ASIC 加速计算芯片。相较 GPU, ASIC 加速计算芯片针对特定应用场景设计具备高性能和低功耗特点,其专用性优势更利于 云服务商的软件适配,并且伴随 AI 应用需求量快速增长能分摊 ASIC 芯片前期较大研发成 本,可同时兼具成本、效率等优势。2025 年 6 月,Marvell 在 Custom AI Investor Event 上修 2028 年 AI 定制芯片市场规模预测至 554 亿美金,2024-2028 年 CAGR 达 53%。看 好 AI 加速芯片定制进一步渗透至终端芯片领域,国内定制芯片服务厂商亦有望充分受益定 制芯片市场规模的快速增长,国内产业链相关公司包括翱捷科技、芯原股份、灿芯股份。
PCB:AI 驱动高端 PCB 需求在 2026 年加速释放
AI 算力 PCB 进入量价齐升阶段,高端化迭代趋势明显
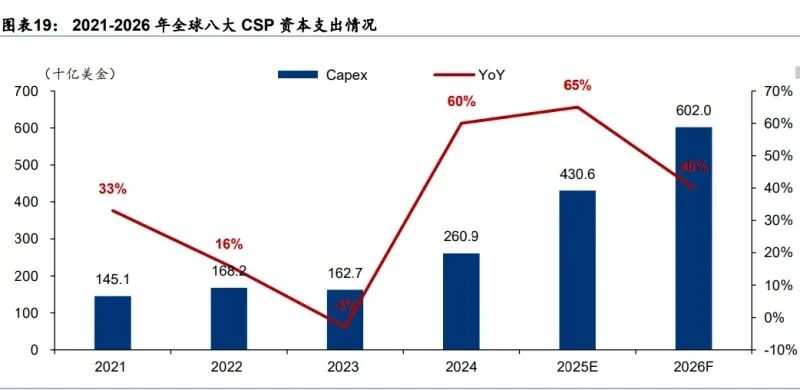
近年来,随着生成式 AI 和高性能计算的快速发展,数据中心服务器成为 PCB 行业最具活 力的下游领域。根据胜宏科技招股书,2024 年全球 AI 及高性能计算领域 PCB 市场规模为 60 亿美元,预计 2029 年将达到 150 亿美元,24-29 年复合增长率高达 20.1%,远高于整 体 PCB 市场复合增速 4.6%。
同时,AI 服务器、网络交换机、光模块等算力类终端对 PCB 的供给规格提出了更高要求, 正推动 PCB 产品向多层化、高精度和高可靠性的方向迭代。根据沙利文研究预测,14 层及 以上高多层板、高阶 HDI 等高端产品市场份额持续增长,2024-2029 年复合增速均显著高 于行业均值。展望未来,看好 AI 服务器平台升级驱动板侧价值量持续提升,助推高多层 PCB 与高阶 HDI 成为行业核心增量,并带动高频高速覆铜板及其前端材料迎来行业扩容。
未来技术迭代趋势 1:CCL 材料向 M8/M9 升级
CCL 作为 PCB 核心基材,其性能直接决定 PCB 的信号传输速度、损耗和可靠性。业界常 用松下Megtron系列作为CCL材料性能标杆,主要衡量指标为介电常数 Dk和损耗因子Df, 指标越低越适用于高频高速场景。AI 算力提升驱动 PCB 向更高层数和更精细线路发展,传 统 CCL 材料无法满足低损耗要求,而 M8/M9 是当前最高等级材料,可支持单通道 224Gbps 传输需求。CCL 材料升级将推动行业产业链向高附加值材料和配套供应转移,上游原材料 商(高纯树脂和石英纤维生产商)受益,中游铜箔、玻纤布生产商也需推出 HVLP4 铜箔等 配套产品,PCB 成本结构倾向于上升,市场格局趋于集中。联茂电子、台光电、台燿科技 等中国台湾厂商已量产 M8 并积极试样 M9;中国大陆生益科技、华正新材等也加速布局 M8 并试产验证 M9。
未来技术迭代趋势 2:CoWoP 封装带动 mSAP 工艺,PCB 环节价值量有望大幅提升
英伟达计划在后续 GPU 封装中尝试 CoWoP 方案,简化 CoWoS 的中间层,直接使用 PCB 取代载板,将芯片封装于 PCB 上。该方案目前处于研发阶段,预计 2028 年后推出,加工 方式倾向于采用 SLP 工艺。SLP 作为更高规格的 HDI,其线宽/线距介于 ABF 载板和传统 HDI 之间,最低可达 15-18μm,BGA pitch 约 110μm。从价值量而言,为满足 CoWoP 封装标准,PCB 价值量将大幅提升。
2026 年服务器/交换机/光模块驱动高端 PCB 需求攀升,看好 ASIC 成为增长新驱动
进入 2026 年,英伟达新一代 AI 服务器平台(GB300、Rubin)有望批量上量,全球头部云 服务商自研 ASIC 加速落地,加之高速交换机与光模块需求增长,我们预计算力 PCB 需求 有望达人民币 1000 亿元,同比大幅提升。尤其 ASIC 板卡因更复杂的系统和更高的性能目 标,对单卡 PCB价值拉动更为显著。2026年随海外云厂 ASIC 项目的推进,搭载这些 ASIC 芯片的 AI 服务器陆续出货,我们测算这些项目将在 2026 年给 PCB 厂商带来 300 亿元以 上的需求,成为 PCB 板块增长的新驱动。
高端产能持续吃紧,关注 PCB 公司新产能投放节奏
2025 年初以来 PCB 行业高端产能紧缺成为市场焦点。由于 PCB 设备采购和产线认证周期 较长,叠加海外新厂投产需经历爬坡期,短期缺口难以快速弥补,我们认为供给端约束或 将助推 PCB 板块在 2026 年延续高景气的特征。 PCB 公司已加速新产能建设应对高端需求。面对高端运算类 PCB 的结构性景气,行业龙 头正加速高多层板、高阶 HDI 等新产线的投资扩充。国内企业不仅持续扩建中国大陆本地 高端厂区,更积极布局泰国、越南等东南亚基地,以抓住国际客户供应链多元化与本地化 趋势。鹏鼎控股、胜宏科技、深南电路等已披露数十亿元甚至上百亿元级别的扩产计划, 海外工厂陆续进入认证与量产阶段。我们预计高端产能建设更积极、新产线良率爬坡更顺 利的 PCB 企业在 2026 年有望获取更多 AI 类订单或突破更多 AI 类客户。
存储:AI 驱动需求快速增长,周期继续向上
价格:4Q25 DRAM/NAND 价格环增扩大,看好 1H26 存储价格进一步上行
 (报告来源:华泰证券。本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
(报告来源:华泰证券。本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)>>>查看更多:股市要闻
