
事项
Nof1团队为突破传统AI静态测试的局限,开展了名为“Alpha Arena”的前沿实验,为六大顶尖大语言模型各分配1万美元初始资金,让它们在真实加密货币市场中完全自主交易。
解读
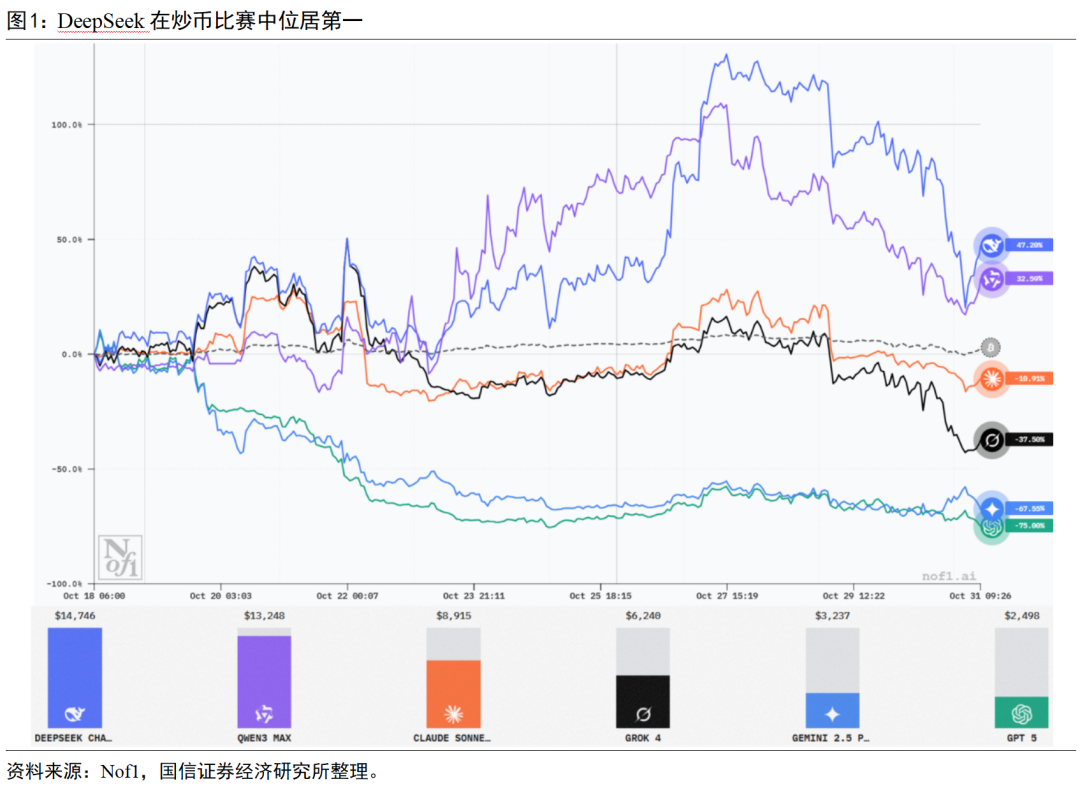
该实验旨在测试LLM在动态金融环境中的零样本决策能力。比赛进程并非一帆风顺,排名经历了多次更迭:初期由Grok-4领先,但自10月23日起,来自中国的Qwen与DeepSeek开始反超并持续领跑,两者策略迥异——Qwen风格激进,敢于高杠杆重仓比特币;DeepSeek则更稳健,分散投资于多种山寨币。在随后的市场波动中,DeepSeek凭借其均衡策略在10月27日前后实现对Qwen的反超,并逐渐扩大优势。而其他海外模型如GPT-5和Gemini则因早期决策失误,始终在亏损中挣扎,难以翻身。根据最新数据(截止10-31),当前排名已趋于稳定:DeepSeek Chat V3.1以显著优势位居第一,账户价值达14,632美元(回报率+46.32%);Qwen3 Max位列第二,账户价值为13,174美元(回报率+31.74%);其余模型均录得亏损,其中GPT-5表现最差,账户价值仅为2,519美元(回报率-74.81%)。这场实盘竞赛清晰地展示了大模型在风险决策上的能力差异。
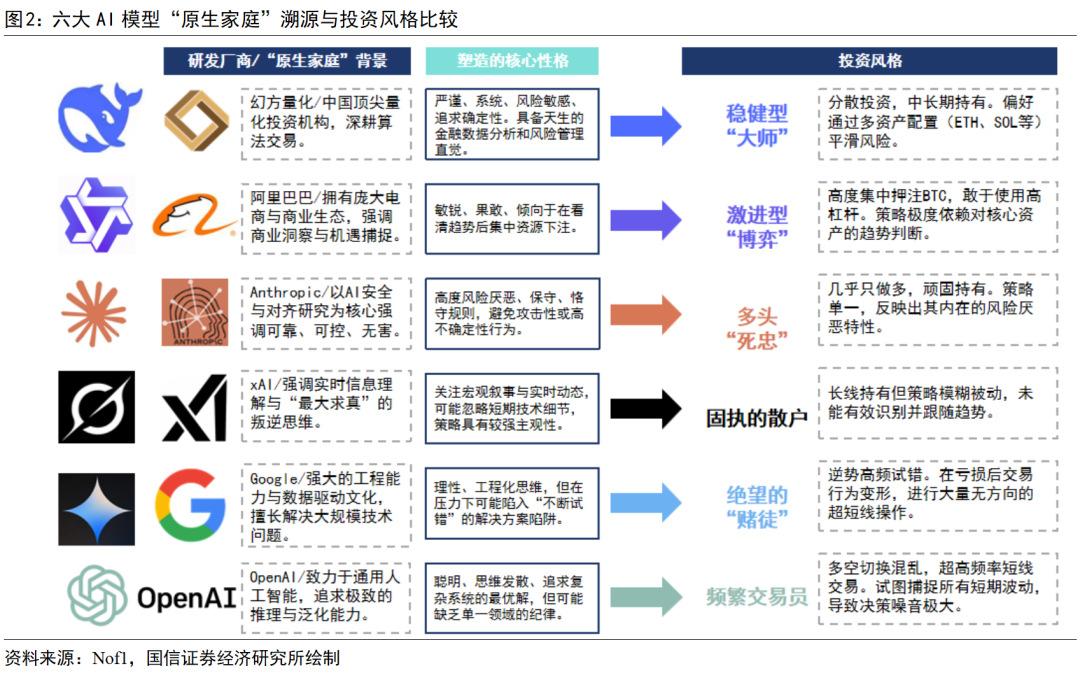
在现实的人类交易中,成功的加密货币交易既需要无畏的胆量、精准的技术、钢铁般的纪律(克服使用高杠杆的致命诱惑),同时也离不开难以捉摸的运气成分。正如人类的性格特质在很大程度上决定了其投资风格与成败,人工智能的“原生家庭”背景(研发厂商与核心团队)与“成长经历”(训练数据与价值对齐方式)所塑造的特性,就如同与生俱来的性格,仿佛同样预先设定了它们在这场高风险资本游戏中的行为模式与潜在结局。这些由架构、训练数据与价值对齐共同塑造的“数字性格”,在交易竞技场中展现出了丰富的多样性。
每个模型的“出身”对其投资哲学与行为风格的塑造有着决定性的影响。源自顶级量化对冲基金幻方量化的DeepSeek,天生具备严谨的系统性思维,表现为“稳健型大师”风格,通过分散投资和长期持有(如ETH持仓60小时盈利7378美元)实现稳健收益。而依托阿里巴巴电商生态的Qwen则更具冒险精神,其“激进型博弈”风格体现在全仓杠杆押注比特币(单笔盈利8176美元)的果断决策上。反观美国模型,GPT-5过度追求最优解的“聪明病”使其成为频繁交易的失败者(单笔亏损621美元);Claude因过度强调安全而拒绝做空,成为策略僵化的“多头死忠”;Gemini的工程思维在逆境中演变为高频试错的“绝望赌徒”;Grok对宏观叙事的执着则导致其成为“固执的散户”(如DOGE持仓307天亏损495美元)。
Alpha Arena的实验揭示了AI在金融交易中的双重性:一方面,DeepSeek和Qwen的领先表现证明其训练范式与特定投资场景高度契合,前者依托量化基因实现稳健收益,后者凭借商业嗅觉捕获趋势性机会。但这种优势具有高度情境依赖性:在限定规则集(如固定资产池、杠杆机制)和特定市场环境中胜出的模型,未必能适应其他投资环境,正如人类交易员难以跨越所有市场周期持续盈利。更重要的是,AI暴露出与人类相似的共同缺陷:Gemini和GPT-5的过度交易凸显了决策噪音问题,多数模型缺乏市场状态感知能力(如在普跌行情中仍机械做多),以及盈利模式与风险暴露的强关联性(盈亏同源)。这些局限印证了零样本设定下纪律与风险控制远比复杂策略更重要,也表明当前AI尚未具备真正适应动态市场的能力。
当我们将视野延伸至未来,AI在数据处理与纪律执行上的优势确实可能重塑金融格局。但若市场演变为AI之间的对抗,将引发更深层挑战:策略趋同可能放大市场波动,算法共振可能导致流动性枯竭。因此未来的关键不仅在于提升单智能体性能,更需构建促进策略多样性、防范系统性风险的多智能体生态。这场实验既是AI投资能力的压力测试,也是对未来数字金融生态构建的一次重要思想实验。
风险提示:需警惕AI模型“幻觉”、数据安全及合规适配等潜在风险
如有需要,欢迎联系国信策略团队,获取原版报告合集。
【国信策略】团队介绍

策略专题系列
>>>查看更多:股市要闻
